News gathered 2024-12-20
(date: 2024-12-20 07:09:59)
@IIIF Mastodon feed (date: 2024-12-20, from: IIIF Mastodon feed)
Join us in the new year for "HDR Images via Image API."
We’ll welcome Christian Mahnke to demo a proof of concept for a
#IIIF
Image API endpoint with UltraHDR tiles & present a proposal to
indicate technical rendering hints to Image API clients.
Zoom info 👉: iiif.io/community
https://glammr.us/@IIIF/113685726572804475
Not The Bear Shown
date: 2024-12-20, updated: 2024-12-20, from: One Foot Tsunami
https://onefoottsunami.com/2024/12/20/not-the-bear-shown/
@Dave Winer’s linkblog (date: 2024-12-20, from: Dave Winer’s linkblog)
You can favor AOC without making it about age. And know there are people listening who tune you out at the first sign of that uniquely Democratic Party hypocrisy. (Could have something to do with losing elections too, btw.)
https://www.slowboring.com/p/aoc-deserved-the-oversight-job?r=etla&triedRedirect=true
@Dave Winer’s linkblog (date: 2024-12-20, from: Dave Winer’s linkblog)
What would a government shutdown mean for you?
https://www.poynter.org/fact-checking/2024/why-is-the-government-shutting-down/
@Dave Winer’s linkblog (date: 2024-12-20, from: Dave Winer’s linkblog)
Staffers at The New York Times on the Books They Enjoyed in 2024.
https://www.nytimes.com/2024/12/20/books/review/staff-picks-books.html
@Dave Winer’s linkblog (date: 2024-12-20, from: Dave Winer’s linkblog)
After reading a few articles about Mike McCue’s announced Surf product I asked meta.ai to explain how it’s different from social web app like threads, Bluesky, twitter.
https://bsky.app/profile/scripting.com/post/3ldq6zu5oon23
@Dave Winer’s linkblog (date: 2024-12-20, from: Dave Winer’s linkblog)
The Ghosts in the Machine, by Liz Pelly.
https://harpers.org/archive/2025/01/the-ghosts-in-the-machine-liz-pelly-spotify-musicians/
December in LLMs has been a lot
date: 2024-12-20, updated: 2024-12-20, from: Simon Willison’s Weblog
I had big plans for December: for one thing, I was hoping to get to an actual RC of Datasette 1.0, in preparation for a full release in January. Instead, I’ve found myself distracted by a constant barrage of new LLM releases.
On December 4th Amazon introduced the Amazon Nova family of multi-modal models - clearly priced to compete with the excellent and inexpensive Gemini 1.5 series from Google. I got those working with LLM via a new llm-bedrock plugin.
The next big release was Llama 3.3 70B-Instruct, on December 6th. Meta claimed that this 70B model was comparable in quality to their much larger 405B model, and those claims seem to hold weight.
I wrote about how I can now run a GPT-4 class model on my laptop - the same laptop that was running a GPT-3 class model just 20 months ago.
Llama 3.3 70B has started showing up from API providers now, including super-fast hosted versions from both Groq (276 tokens/second) and Cerebras (a quite frankly absurd 2,200 tokens/second). If you haven’t tried Val Town’s Cerebras Coder demo you really should.
I think the huge gains in model efficiency are one of the defining stories of LLMs in 2024. It’s not just the local models that have benefited: the price of proprietary hosted LLMs has dropped through the floor, a result of both competition between vendors and the increasing efficiency of the models themselves.
Last year the running joke was that every time Google put out a new Gemini release OpenAI would ship something more impressive that same day to undermine them.
The tides have turned! This month Google shipped four updates that took the wind out of OpenAI’s sails.
The first was gemini-exp-1206 on December 6th, an experimental model that jumped straight to the top of some of the leaderboards. Was this our first glimpse of Gemini 2.0?
That was followed by Gemini 2.0 Flash on December 11th, the first official release in Google’s Gemini 2.0 series. The streaming support was particularly impressive, with https://aistudio.google.com/live demonstrating streaming audio and webcam communication with the multi-modal LLM a full day before OpenAI released their own streaming camera/audio features in an update to ChatGPT.
Then this morning Google shipped Gemini 2.0 Flash “Thinking mode”, their version of the inference scaling technique pioneered by OpenAI’s o1. I did not expect Gemini to ship a version of that before 2024 had even ended.
OpenAI have one day left in their 12 Days of OpenAI event. Previous highlights have included the full o1 model (an upgrade from o1-preview) and o1-pro, Sora (later upstaged a week later by Google’s Veo 2), Canvas (with a confusing second way to run Python), Advanced Voice with video streaming and Santa and a very cool new WebRTC streaming API, ChatGPT Projects (pretty much a direct lift of the similar Claude feature) and the 1-800-CHATGPT phone line.
Tomorrow is the last day. I’m not going to try to predict what they’ll launch, but I imagine it will be something notable to close out the year.
Blog entries
- Gemini 2.0 Flash “Thinking mode”
- Building Python tools with a one-shot prompt using uv run and Claude Projects
- Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode
- ChatGPT Canvas can make API requests now, but it’s complicated
- I can now run a GPT-4 class model on my laptop
- Prompts.js
- First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
- Storing times for human events
- Ask questions of SQLite databases and CSV/JSON files in your terminal
Releases
-
llm-gemini
0.8 - 2024-12-19
LLM plugin to access Google’s Gemini family of models -
datasette-enrichments-slow
0.1 - 2024-12-18
An enrichment on a slow loop to help debug progress bars -
llm-anthropic
0.11 - 2024-12-17
LLM access to models by Anthropic, including the Claude series -
llm-openrouter
0.3 - 2024-12-08
LLM plugin for models hosted by OpenRouter -
prompts-js
0.0.4 - 2024-12-08
async alternatives to browser alert() and prompt() and confirm() -
datasette-enrichments-llm
0.1a0 - 2024-12-05
Enrich data by prompting LLMs -
llm
0.19.1 - 2024-12-05
Access large language models from the command-line -
llm-bedrock
0.4 - 2024-12-04
Run prompts against models hosted on AWS Bedrock -
datasette-queries
0.1a0 - 2024-12-03
Save SQL queries in Datasette -
datasette-llm-usage
0.1a0 - 2024-12-02
Track usage of LLM tokens in a SQLite table -
llm-mistral
0.9 - 2024-12-02
LLM plugin providing access to Mistral models using the Mistral API -
llm-claude-3
0.10 - 2024-12-02
LLM plugin for interacting with the Claude 3 family of models -
datasette
0.65.1 - 2024-11-29
An open source multi-tool for exploring and publishing data -
sqlite-utils-ask
0.2 - 2024-11-24
Ask questions of your data with LLM assistance -
sqlite-utils
3.38 - 2024-11-23
Python CLI utility and library for manipulating SQLite databases
TILs
- Fixes for datetime UTC warnings in Python - 2024-12-12
- Publishing a simple client-side JavaScript package to npm with GitHub Actions - 2024-12-08
- GitHub OAuth for a static site using Cloudflare Workers - 2024-11-29
<p>Tags: <a href="https://simonwillison.net/tags/google">google</a>, <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/weeknotes">weeknotes</a>, <a href="https://simonwillison.net/tags/openai">openai</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/chatgpt">chatgpt</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/gemini">gemini</a>, <a href="https://simonwillison.net/tags/o1">o1</a></p> https://simonwillison.net/2024/Dec/20/december-in-llms-has-been-a-lot/#atom-everything
Building effective agents
date: 2024-12-20, updated: 2024-12-20, from: Simon Willison’s Weblog
My principal complaint about the term “agents” is that while it has many different potential definitions most of the people who use it seem to assume that everyone else shares and understands the definition that they have chosen to use.This outstanding piece by Erik Schluntz and Barry Zhang at Anthropic bucks that trend from the start, providing a clear definition that they then use throughout.
They discuss “agentic systems” as a parent term, then define a distinction between “workflows” - systems where multiple LLMs are orchestrated together using pre-defined patterns - and “agents”, where the LLMs “dynamically direct their own processes and tool usage”. This second definition is later expanded with this delightfully clear description:
Agents begin their work with either a command from, or interactive discussion with, the human user. Once the task is clear, agents plan and operate independently, potentially returning to the human for further information or judgement. During execution, it’s crucial for the agents to gain “ground truth” from the environment at each step (such as tool call results or code execution) to assess its progress. Agents can then pause for human feedback at checkpoints or when encountering blockers. The task often terminates upon completion, but it’s also common to include stopping conditions (such as a maximum number of iterations) to maintain control.
That’s a definition I can live with!
They also introduce a term that I really like: the augmented LLM. This is an LLM with augmentations such as tools - I’ve seen people use the term “agents” just for this, which never felt right to me.
The rest of the article is the clearest practical guide to building systems that combine multiple LLM calls that I’ve seen anywhere.
Most of the focus is actually on workflows. They describe five different patterns for workflows in detail:
- Prompt chaining, e.g. generating a document and then translating it to a separate language as a second LLM call
- Routing, where an initial LLM call decides which model or call should be used next (sending easy tasks to Haiku and harder tasks to Sonnet, for example)
- Parallelization, where a task is broken up and run in parallel (e.g. image-to-text on multiple document pages at once) or processed by some kind of voting mechanism
- Orchestrator-workers, where a orchestrator triggers multiple LLM calls that are then synthesized together, for example running searches against multiple sources and combining the results
- Evaluator-optimizer, where one model checks the work of another in a loop
These patterns all make sense to me, and giving them clear names makes them easier to reason about.
When should you upgrade from basic prompting to workflows and then to full agents? The authors provide this sensible warning:
When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all.
But assuming you do need to go beyond what can be achieved even with the aforementioned workflow patterns, their model for agents may be a useful fit:
Agents can be used for open-ended problems where it’s difficult or impossible to predict the required number of steps, and where you can’t hardcode a fixed path. The LLM will potentially operate for many turns, and you must have some level of trust in its decision-making. Agents’ autonomy makes them ideal for scaling tasks in trusted environments.
The autonomous nature of agents means higher costs, and the potential for compounding errors. We recommend extensive testing in sandboxed environments, along with the appropriate guardrails
They also warn against investing in complex agent frameworks before you’ve exhausted your options using direct API access and simple code.
The article is accompanied by a brand new set of cookbook recipes illustrating all five of the workflow patterns. The Evaluator-Optimizer Workflow example is particularly fun, setting up a code generating prompt and an code reviewing evaluator prompt and having them loop until the evaluator is happy with the result.
<p><small></small>Via <a href="https://x.com/HamelHusain/status/1869935867940540596">Hamel Husain</a></small></p>
<p>Tags: <a href="https://simonwillison.net/tags/prompt-engineering">prompt-engineering</a>, <a href="https://simonwillison.net/tags/anthropic">anthropic</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/llm-tool-use">llm-tool-use</a>, <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/ai-agents">ai-agents</a></p> https://simonwillison.net/2024/Dec/20/building-effective-agents/#atom-everything
Quoting Marcus Hutchins
date: 2024-12-20, updated: 2024-12-20, from: Simon Willison’s Weblog
50% of cybersecurity is endlessly explaining that consumer VPNs don’t address any real cybersecurity issues. They are basically only useful for bypassing geofences and making money telling people they need to buy a VPN.
Man-in-the-middle attacks on Public WiFi networks haven’t been a realistic threat in a decade. Almost all websites use encryption by default, and anything of value uses HSTS to prevent attackers from downgrading / disabling encryption. It’s a non issue.
<p>Tags: <a href="https://simonwillison.net/tags/encryption">encryption</a>, <a href="https://simonwillison.net/tags/vpn">vpn</a>, <a href="https://simonwillison.net/tags/https">https</a>, <a href="https://simonwillison.net/tags/security">security</a></p> https://simonwillison.net/2024/Dec/20/marcus-hutchins/#atom-everything
@Dave Winer’s linkblog (date: 2024-12-20, from: Dave Winer’s linkblog)
Nate Bargatze: The baffling rise of the most inoffensive comedian alive.
Understanding Computer Networks by Analogy
date: 2024-12-20, from: Memo Garcia blog
I’m writing this for the version of me back in university who struggled to grasp networking concepts. This isn’t a full map of the networking world, but it’s a starting point. If you’re also finding it tricky to understand some of the ideas that make the internet works, I hope this helps.
I’m sticking with analogies here instead of going deep into technical terms—you can find those easily anywhere. I just enjoy looking at the world from different perspectives. It’s fascinating how many connections you can spot when you approach things from a new angle.
https://memo.mx/posts/understanding-computer-networks-by-analogy/
@Dave Winer’s linkblog (date: 2024-12-20, from: Dave Winer’s linkblog)
The GOP Is Treating Musk Like He’s in Charge.
Gemini 2.0 Flash “Thinking mode”
date: 2024-12-19, updated: 2024-12-19, from: Simon Willison’s Weblog
Those new model releases just keep on flowing. Today it’s Google’s
snappily named gemini-2.0-flash-thinking-exp, their first
entrant into the o1-style inference scaling class of models. I posted
about
a
great essay about the significance of these just this morning.
From the Gemini model documentation:
Gemini 2.0 Flash Thinking Mode is an experimental model that’s trained to generate the “thinking process” the model goes through as part of its response. As a result, Thinking Mode is capable of stronger reasoning capabilities in its responses than the base Gemini 2.0 Flash model.
I just shipped llm-gemini 0.8 with support for the model. You can try it out using LLM like this:
llm install -U llm-gemini
# If you haven't yet set a gemini key:
llm keys set gemini
# Paste key here
llm -m gemini-2.0-flash-thinking-exp-1219 "solve a harder variant of that goat lettuce wolf river puzzle"
It’s a very talkative model - 2,277 output tokens answering that prompt.
A more interesting example
The best source of example prompts I’ve found so far is the Gemini 2.0 Flash Thinking cookbook - a Jupyter notebook full of demonstrations of what the model can do.
My favorite so far is this one:
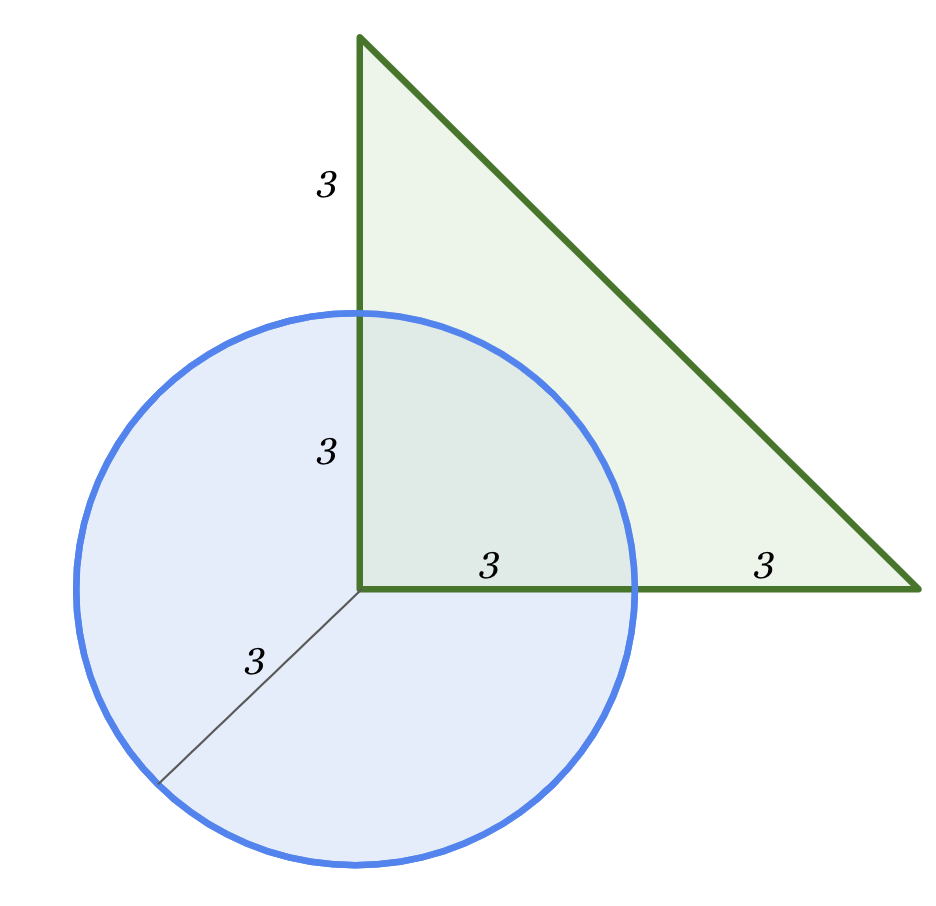
What’s the area of the overlapping region?
This model is multi-modal!
Here’s how to run that example using llm-gemini:
llm -m gemini-2.0-flash-thinking-exp-1219 \
-a https://storage.googleapis.com/generativeai-downloads/images/geometry.png \
"What's the area of the overlapping region?"
Here’s the full response, complete with MathML working. The eventual conclusion:
The final answer is 9π/4
That’s the same answer as Google provided in their example notebook, so I’m presuming it’s correct. Impressive!
How about an SVG of a pelican riding a bicycle?
llm -m gemini-2.0-flash-thinking-exp-1219 \
"Generate an SVG of a pelican riding a bicycle"
Here’s the full response. Interestingly it slightly corrupted the start of its answer:
This thought process involves a combination of visual thinking, knowledge of SVG syntax, and iterative refinement. The key is to break down the problem into manageable parts and build up the image piece by piece. Even experienced SVG creators often go through several adjustments before arriving at the final version.00” height=“250” viewBox=“0 0 300 250” fill=“none” xmlns=“http://www.w3.org/2000/svg”>
<g>
<!– Bicycle Frame –>
After I manually repaired that to add the <svg opening
tag I got this:
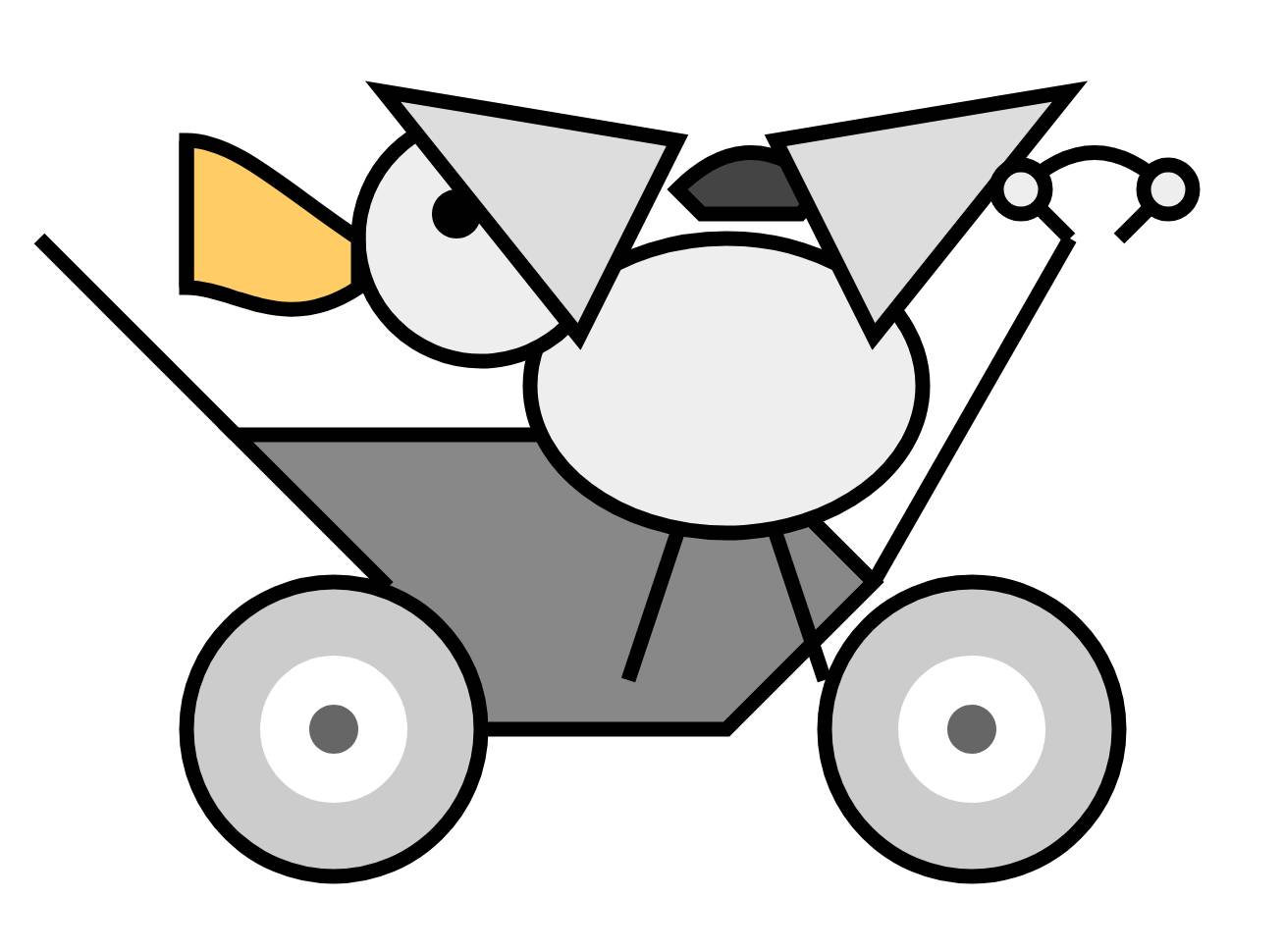
So maybe not an artistic genius, but it’s interesting to read through its chain of thought for that task.
Who’s next?
It’s very clear now that inference scaling is the next big area of research for the large labs. We’ve seen models from OpenAI (o1), Qwen (QwQ), DeepSeek (DeepSeek-R1-Lite-Preview) and now Google Gemini. I’m interested to hear if Anthropic or Meta or Mistral or Amazon have anything cooking in this category.
<p>Tags: <a href="https://simonwillison.net/tags/google">google</a>, <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/llm">llm</a>, <a href="https://simonwillison.net/tags/gemini">gemini</a>, <a href="https://simonwillison.net/tags/o1">o1</a>, <a href="https://simonwillison.net/tags/pelican-riding-a-bicycle">pelican-riding-a-bicycle</a>, <a href="https://simonwillison.net/tags/inference-scaling">inference-scaling</a></p> https://simonwillison.net/2024/Dec/19/gemini-thinking-mode/#atom-everything
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
One day you could be looking
Through an old book in rainy weather
You see a picture of her smiling at you
When you were still together
You could be walking down the street
And who should you chance to meet
But that same old smile you've been thinking of all day
https://www.youtube.com/watch?v=cA46ZNjrzeY
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
The About page for my blog in 2003. It's pretty funny, if you like that kind of stuff.
http://essaysfromexodus.scripting.com/whatIsScriptingNews
Asus announces the NUC 14 Pro AI Lunar Lake mini PC
date: 2024-12-19, from: Liliputing
The Asus NUC 14 Pro AI is a compact desktop computer with support for up to an Intel Core Ultra 9 288V “Lunar Lake” processor and support for WiFi 7, 2.5 Gb Ethernet, and Thunderbolt 4. Asus first added the computer to its website in September when Intel first unveiled the Lunar Lake processor lineup, […]
The post Asus announces the NUC 14 Pro AI Lunar Lake mini PC appeared first on Liliputing.
https://liliputing.com/asus-announces-the-nuc-14-pro-ai-lunar-lake-mini-pc/
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
Musk's misinformation campaign helps block Congress' spending deal.
https://thehill.com/policy/technology/5049450-musk-floods-x-with-spending-bill-misinformation/
Ventiva unveils an active cooling solution for fanless laptops
date: 2024-12-19, from: Liliputing
Most laptop computers have fans to help dissipate heat generated by the CPU and other hardware. But fans generate noise, have a habit of getting clogged with dust, and like most moving parts, an sometimes break down. Fanless PCs have been around for years, but they usually come with trade-offs like lower-power processors that generate […]
The post Ventiva unveils an active cooling solution for fanless laptops appeared first on Liliputing.
https://liliputing.com/ventiva-unveils-an-active-cooling-solution-for-fanless-laptops-up/
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
America’s Bird-Flu Luck Has Officially Run Out.
Swift Prospective Vision: Accessors
date: 2024-12-19, from: Michael Tsai
John McCall (forum): However, this approach has significant problems. The biggest is that the get accessor has to return an independent value. If the accessor is just returning a value stored in memory, which is very common for data structures, this means the value has to be copied.[…]This vision document lays out the design space […]
https://mjtsai.com/blog/2024/12/19/swift-prospective-vision-accessors/
Delta Adds External Purchase Link in US
date: 2024-12-19, from: Michael Tsai
John Voorhees: Delta, the MacStories Selects App of the Year, received an important update today that allows users of the game emulator to support its development via Patreon from inside the app. Existing patrons can connect their Patreon accounts from Delta’s settings, too, allowing them to access perks like alternative app icons and experimental features.This […]
https://mjtsai.com/blog/2024/12/19/delta-adds-external-purchase-link-in-us/
SwiftUWhy
date: 2024-12-19, from: Michael Tsai
John Siracusa: Welcome to my new series on things I don’t understand about Apple’s premier user interface framework.[…]To be clear, these are things I don’t understand, not necessarily things that are “wrong.” They sure look wrong (or at least “suboptimal”) to me! But maybe there are good reasons, and I just don’t know them yet. […]
https://mjtsai.com/blog/2024/12/19/swiftuwhy/
Cascable Studio Rejected From the App Store
date: 2024-12-19, from: Michael Tsai
Daniel Kennett: I’ve been shipping apps to the App Store for well over fifteen years now, and although there are App Review horror stories aplenty, I’ve always hoped I’d never be in a position to write one myself.[…]What you just scrolled past was the history of my (eventually successful) attempt to get the new Mac […]
https://mjtsai.com/blog/2024/12/19/cascable-studio-rejected-from-the-app-store/
Time to Vote for the December 2024 + Post Topic
date: 2024-12-19, from: Computer ads from the Past
Your options are a programming language, a multimedia program, and a printer.
https://computeradsfromthepast.substack.com/p/time-to-vote-for-the-december-2024
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
$44 billion to buy Twitter looks like the biggest bargain ever. From that seat he controls the spending of Congress. The budget deal he just killed would have spent hundreds of billions.
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
The period of left-wing illiberalism that began about a decade ago seems to have drawn to a close. The final cause of death was the reelection of Donald Trump.
Daily Deals (12-19-2024)
date: 2024-12-19, from: Liliputing
Laptops with OLED displays usually have hefty price tags. But laptops that are a generation or two old often get significant price cuts when companies are looking to clear out remaining inventory. And those two trends are colliding in a couple of deals on low-cost laptops with reasonably good specs and reasonably low price tags. […]
The post Daily Deals (12-19-2024) appeared first on Liliputing.
https://liliputing.com/daily-deals-12-19-2024/
ONEXPLAYER G1 is an 8.8 inch mini-laptop for gaming (AMD Strix Point and a detachable keyboard)
date: 2024-12-19, from: Liliputing
The ONEXPLAYER G1 is either a mini-laptop that an also be used as a handheld gaming system, or a gaming handheld that can also be used as a general-purpose laptop. It’s a compact computer with an 8.8 inch display, an AMD Strix Point processor, and a QWERTY keyboard that’s just (barely) large enough for touch typing. […]
The post ONEXPLAYER G1 is an 8.8 inch mini-laptop for gaming (AMD Strix Point and a detachable keyboard) appeared first on Liliputing.
Is AI progress slowing down?
date: 2024-12-19, updated: 2024-12-19, from: Simon Willison’s Weblog
This piece by Arvind Narayanan, Sayash Kapoor and Benedikt Ströbl is the single most insightful essay about AI and LLMs I’ve seen in a long time. It’s long and worth reading every inch of it - it defies summarization, but I’ll try anyway.The key question they address is the widely discussed issue of whether model scaling has stopped working. Last year it seemed like the secret to ever increasing model capabilities was to keep dumping in more data and parameters and training time, but the lack of a convincing leap forward in the two years since GPT-4 - from any of the big labs - suggests that’s no longer the case.
The new dominant narrative seems to be that model scaling is dead, and “inference scaling”, also known as “test-time compute scaling” is the way forward for improving AI capabilities. The idea is to spend more and more computation when using models to perform a task, such as by having them “think” before responding.
Inference scaling is the trick introduced by OpenAI’s o1 and now explored by other models such as Qwen’s QwQ. It’s an increasingly practical approach as inference gets more efficient and cost per token continues to drop through the floor.
But how far can inference scaling take us, especially if it’s only effective for certain types of problem?
The straightforward, intuitive answer to the first question is that inference scaling is useful for problems that have clear correct answers, such as coding or mathematical problem solving. […] In contrast, for tasks such as writing or language translation, it is hard to see how inference scaling can make a big difference, especially if the limitations are due to the training data. For example, if a model works poorly in translating to a low-resource language because it isn’t aware of idiomatic phrases in that language, the model can’t reason its way out of this.
There’s a delightfully spicy section about why it’s a bad idea to defer to the expertise of industry insiders:
In short, the reasons why one might give more weight to insiders’ views aren’t very important. On the other hand, there’s a huge and obvious reason why we should probably give less weight to their views, which is that they have an incentive to say things that are in their commercial interests, and have a track record of doing so.
I also enjoyed this note about how we are still potentially years behind in figuring out how to build usable applications that take full advantage of the capabilities we have today:
The furious debate about whether there is a capability slowdown is ironic, because the link between capability increases and the real-world usefulness of AI is extremely weak. The development of AI-based applications lags far behind the increase of AI capabilities, so even existing AI capabilities remain greatly underutilized. One reason is the capability-reliability gap — even when a certain capability exists, it may not work reliably enough that you can take the human out of the loop and actually automate the task (imagine a food delivery app that only works 80% of the time). And the methods for improving reliability are often application-dependent and distinct from methods for improving capability. That said, reasoning models also seem to exhibit reliability improvements, which is exciting.
<p><small></small>Via <a href="https://bsky.app/profile/randomwalker.bsky.social/post/3ldnu2gntqs24">@randomwalker.bsky.social</a></small></p>
<p>Tags: <a href="https://simonwillison.net/tags/o1">o1</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/arvind-narayanan">arvind-narayanan</a>, <a href="https://simonwillison.net/tags/inference-scaling">inference-scaling</a></p> https://simonwillison.net/2024/Dec/19/is-ai-progress-slowing-down/#atom-everything
APpaREnTLy THiS iS hoW yoU JaIlBreAk AI
date: 2024-12-19, from: 404 Media Group
Anthropic created an AI jailbreaking algorithm that keeps tweaking prompts until it gets a harmful response.
https://www.404media.co/apparently-this-is-how-you-jailbreak-ai/
Lenovo ThinkBook Plus laptop with a rollable display could launch in 2025
date: 2024-12-19, from: Liliputing
Lenovo has been showing off concept laptops with rollable OLED displays for the past few years. Now Lenovo is said to be preparing to turn that concept into a real device you can actually buy. Evan Blass has shared a set of pictures to Leakmail subscribers that give us a first look at a new Lenovo […]
The post Lenovo ThinkBook Plus laptop with a rollable display could launch in 2025 appeared first on Liliputing.
https://liliputing.com/lenovo-thinkbook-plus-laptop-with-a-rollable-display-could-launch-in-2025/
Enhanced Security with Node-to-Node TLS
date: 2024-12-19, from: Bacalhau Blog
Security at the heart, at the edge, and everywhere in-between.
https://blog.bacalhau.org/p/enhanced-security-with-node-to-node
Marking the 80th Anniversary of “an ever-famous American victory”: A Look at the US National Archive’s Battle of the Bulge Records
date: 2024-12-19, from: National Archives, Text Message blog
Today’s post was written by Duncan Bare, archives technician at the National Archives in College Park. Winston S. Churchill famously described the Battle of the Bulge as “undoubtedly the greatest American battle of the war and […] an ever-famous American victory.”[1] As the German offensive commenced at around 5:30 am on December 16th, 1944, however, … Continue reading Marking the 80th Anniversary of “an ever-famous American victory”: A Look at the US National Archive’s Battle of the Bulge Records
Copyright Abuse Is Getting Luigi Mangione Merch Removed From the Internet
date: 2024-12-19, from: 404 Media Group
Artists, merch sellers, and journalists making and posting Luigi media have become the targets of bogus DMCA claims.
https://www.404media.co/copyright-abuse-is-getting-luigi-mangione-merch-removed-from-the-internet/
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
Krugman proves that there must be a reason to have blogs after all.
http://scripting.com/2024/12/19.html#a155019?title=krugman
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
2010: I love reading Paul Krugman's blog posts.
http://scripting.com/stories/2010/11/02/iLoveReadingPaulKrugmansBl.html
q and qv zsh functions for asking questions of websites and YouTube videos with LLM
date: 2024-12-19, updated: 2024-12-19, from: Simon Willison’s Weblog
q and qv zsh functions for asking questions of websites and YouTube videos with LLM
Spotted these in David Gasquez’szshrc dotfiles: two shell
functions that use my LLM tool
to answer questions about a website or YouTube video.
Here’s how to ask a question of a website:
q https://simonwillison.net/ 'What has Simon written about recently?'
I got back:
Recently, Simon Willison has written about various topics including:
- Building Python Tools - Exploring one-shot applications using Claude and dependency management with
uv.- Modern Java Usage - Discussing recent developments in Java that simplify coding.
- GitHub Copilot Updates - New free tier and features in GitHub Copilot for Vue and VS Code.
- AI Engagement on Bluesky - Investigating the use of bots to create artificially polite disagreements.
- OpenAI WebRTC Audio - Demonstrating a new API for real-time audio conversation with models.
It works by constructing a Jina Reader URL to convert that URL to Markdown, then piping that content into LLM along with the question.
The YouTube one is even more fun:
qv 'https://www.youtube.com/watch?v=uRuLgar5XZw' 'what does Simon say about open source?'
It said (about this 72 minute video):
Simon emphasizes that open source has significantly increased productivity in software development. He points out that before open source, developers often had to recreate existing solutions or purchase proprietary software, which often limited customization. The availability of open source projects has made it easier to find and utilize existing code, which he believes is one of the primary reasons for more efficient software development today.
The secret sauce behind that one is the way it uses yt-dlp
to extract just the subtitles for the video:
local subtitle_url=$(yt-dlp -q --skip-download --convert-subs srt --write-sub --sub-langs "en" --write-auto-sub --print "requested_subtitles.en.url" "$url")
local content=$(curl -s "$subtitle_url" | sed '/^$/d' | grep -v '^[0-9]*$' | grep -v '\-->' | sed 's/<[^>]*>//g' | tr '\n' ' ')
That first line retrieves a URL to the subtitles in WEBVTT format - I
saved
a copy of that here. The second line then uses curl to
fetch them, then sed and grep to remove the
timestamp information, producing
this.
<p><small></small>Via <a href="https://davidgasquez.com/useful-llm-tools-2024/">Useful LLM tools (2024 Edition)</a></small></p>
<p>Tags: <a href="https://simonwillison.net/tags/youtube">youtube</a>, <a href="https://simonwillison.net/tags/llm">llm</a>, <a href="https://simonwillison.net/tags/jina">jina</a>, <a href="https://simonwillison.net/tags/zsh">zsh</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/llms">llms</a></p> https://simonwillison.net/2024/Dec/19/q-and-qv-zsh-functions/#atom-everything
Faking Love for the Boss
date: 2024-12-19, updated: 2024-12-19, from: One Foot Tsunami
https://onefoottsunami.com/2024/12/19/faking-love-for-the-boss/
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
Bidenomics Was Wildly Successful.
https://newrepublic.com/article/189232/bidenomics-success-biden-legacy
Third Eye assistive vision | The MagPi #149
date: 2024-12-19, from: Raspberry Pi News (.com)
This MagPi Monday, we look at Third Eye, a project that uses AI to assist people with visual impairment.
The post Third Eye assistive vision | The MagPi #149 appeared first on Raspberry Pi.
https://www.raspberrypi.com/news/third-eye-assistive-vision-the-magpi-149/
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
Chris Murphy’s Ominous New Warning about Trump Nails It.
https://newrepublic.com/article/189552/transcript-chris-murphys-ominous-new-warning-trump-nails
What just happened
date: 2024-12-19, from: One Useful Thing
A transformative month rewrites the capabilities of AI
https://www.oneusefulthing.org/p/what-just-happened
More Than Watergate: The PRMPA
date: 2024-12-19, from: National Archives, Pieces of History blog
Today’s post on the Presidential Recordings and Materials Preservation Act (PRMPA) comes from Laurel Gray, a processing intern with the Textual Division at the National Archives in Washington, DC. It is the second of a four-part series on the archival ramifications of the Watergate scandal. When President Richard Nixon resigned in August 1974, he signed an agreement … Continue reading More Than Watergate: The PRMPA
https://prologue.blogs.archives.gov/2024/12/19/more-than-watergate-the-prmpa/
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
I’m very confused about how they’re integrating AI and GitHub, but it sounds like it’ll be useful, when I figure out what it is.
https://github.blog/news-insights/product-news/github-copilot-workspace/
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
What happens when the internet disappears?
https://www.theverge.com/24321569/internet-decay-link-rot-web-archive-deleted-culture
Wednesday, December 18, 2024 - notes on the garmin instinct 2 solar - table of contents - background & motivations - the watch - case design, fit, appearance, etc. - display - power - durability - sensors - compass failures - software - on-device interface - mobile apps, etc. - gadgetbridge as an alternative - data syncing - some implications of this device - notes for garmin
date: 2024-12-19, updated: 2024-12-19, from: p1k3.com community feed
Building Python tools with a one-shot prompt using uv run and Claude Projects
date: 2024-12-19, updated: 2024-12-19, from: Simon Willison’s Weblog
I’ve written a lot about how I’ve been using Claude to build one-shot HTML+JavaScript applications via Claude Artifacts. I recently started using a similar pattern to create one-shot Python utilities, using a custom Claude Project combined with the dependency management capabilities of uv.
(In LLM jargon a “one-shot” prompt is a prompt that produces the complete desired result on the first attempt.)
I’ll start with an example of a tool I built that way.
I had another round of battle with Amazon S3 today trying to figure out why a file in one of my buckets couldn’t be accessed via a public URL.
Out of frustration I prompted Claude with a variant of the following (full transcript here):
I can’t access the file at EXAMPLE_S3_URL. Write me a Python CLI tool using Click and boto3 which takes a URL of that form and then uses EVERY single boto3 trick in the book to try and debug why the file is returning a 404
It wrote me this script, which gave me exactly what I needed. I ran it like this:
uv run debug_s3_access.py \
https://test-public-bucket-simonw.s3.us-east-1.amazonaws.com/0f550b7b28264d7ea2b3d360e3381a95.jpg
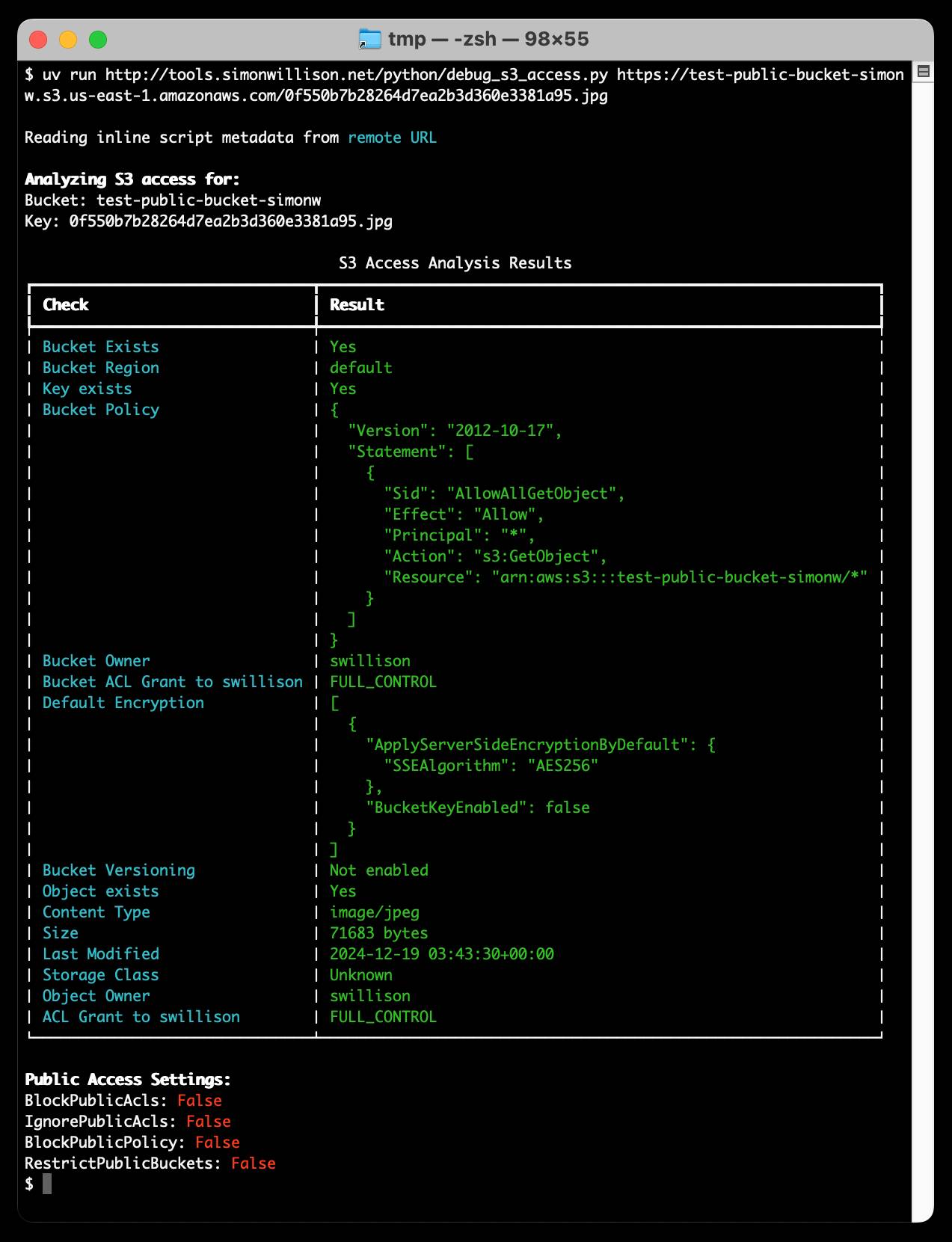
You can see the text output here.
Inline dependencies and uv run
Crucially, I didn’t have to take any extra steps to install any of the dependencies that the script needed. That’s because the script starts with this magic comment:
# /// script # requires-python = ">=3.12" # dependencies = [ # "click", # "boto3", # "urllib3", # "rich", # ] # ///
This is an example of
inline
script dependencies, a feature described in
PEP 723 and implemented
by uv run. Running the script causes uv to
create a temporary virtual environment with those dependencies
installed, a process that takes just a few milliseconds once the
uv cache has been populated.
This even works if the script is specified by a URL! Anyone with
uv installed can run the following command (provided you
trust me not to have replaced the script with something malicious) to
debug one of their own S3 buckets:
uv run http://tools.simonwillison.net/python/debug_s3_access.py \
https://test-public-bucket-simonw.s3.us-east-1.amazonaws.com/0f550b7b28264d7ea2b3d360e3381a95.jpg
Writing these with the help of a Claude Project
The reason I can one-shot scripts like this now is that I’ve set up a Claude Project called “Python app”. Projects can have custom instructions, and I used those to “teach” Claude how to take advantage of inline script dependencies:
You write Python tools as single files. They always start with this comment:
# /// script # requires-python = ">=3.12" # ///These files can include dependencies on libraries such as Click. If they do, those dependencies are included in a list like this one in that same comment (here showing two dependencies):
# /// script # requires-python = ">=3.12" # dependencies = [ # "click", # "sqlite-utils", # ] # ///
That’s everything Claude needs to reliably knock out full-featured Python tools as single scripts which can be run directly using whatever dependencies Claude chose to include.
I didn’t suggest that Claude use
rich for the
debug_s3_access.py script earlier but it decided to use it
anyway!
I’ve only recently started experimenting with this pattern but it seems to work really well. Here’s another example - my prompt was:
Starlette web app that provides an API where you pass in ?url= and it strips all HTML tags and returns just the text, using beautifulsoup
Here’s the chat transcript and the raw code it produced. You can run that server directly on your machine (it uses port 8000) like this:
uv run https://gist.githubusercontent.com/simonw/08957a1490ebde1ea38b4a8374989cf8/raw/143ee24dc65ca109b094b72e8b8c494369e763d6/strip_html.py
Then visit
http://127.0.0.1:8000/?url=https://simonwillison.net/ to
see it in action.
Custom instructions
The pattern here that’s most interesting to me is using custom
instructions or system prompts to show LLMs how to implement new
patterns that may not exist in their training data. uv run
is less than a year old, but providing just a short example is enough to
get the models to write code that takes advantage of its capabilities.
I have a similar set of custom instructions I use for creating single page HTML and JavaScript tools, again running in a Claude Project:
Never use React in artifacts - always plain HTML and vanilla JavaScript and CSS with minimal dependencies.
CSS should be indented with two spaces and should start like this:
<style> * { box-sizing: border-box; }Inputs and textareas should be font size 16px. Font should always prefer Helvetica.
JavaScript should be two space indents and start like this:
<script type="module"> // code in here should not be indented at the first level
Most of the tools on my tools.simonwillison.net site were created using versions of this custom instructions prompt.
<p>Tags: <a href="https://simonwillison.net/tags/aws">aws</a>, <a href="https://simonwillison.net/tags/python">python</a>, <a href="https://simonwillison.net/tags/s3">s3</a>, <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/prompt-engineering">prompt-engineering</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/ai-assisted-programming">ai-assisted-programming</a>, <a href="https://simonwillison.net/tags/claude">claude</a>, <a href="https://simonwillison.net/tags/claude-artifacts">claude-artifacts</a>, <a href="https://simonwillison.net/tags/uv">uv</a></p> https://simonwillison.net/2024/Dec/19/one-shot-python-tools/#atom-everything
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
How Trump gets his hair done.
How to shrink ONNX files
date: 2024-12-19, from: Peter Warden
I’ve been using the ONNX Runtime a lot recently, and while it has been a lot of fun, there are a few things I’ve missed from the TensorFlow Lite world. The biggest (no pun intended) is the lack of tools to shrink the model file size, something that’s always been essential in the mobile app […]
https://petewarden.com/2024/12/19/how-to-shrink-onnx-files/
“We Are Getting Lasered”: Nearly a Dozen Planes Lasered Last Night During New Jersey Drone Panic
date: 2024-12-19, from: 404 Media Group
Air traffic control audio reviewed by 404 Media shows 11 aircraft near New Jersey reporting people shining lasers at them during the ongoing drone panic.
@Dave Winer’s linkblog (date: 2024-12-19, from: Dave Winer’s linkblog)
"We should spend a few months marketing the Democratic Party."
https://bsky.app/profile/did:plc:oety7qbfx7x6exn2ytrwikmr/post/3lbuy3qlb7s2v
AI Engineering Primer
date: 2024-12-19, updated: 2024-12-19, from: Tom Kellog blog
How do you get up to speed with AI engineering? Unfortunately, I don’t know of any good consolidated resources, so I’m going to attempt to make one here. My first attempt at this focused more on what an AI engineer is and made only a feeble attempt at providing resources to get started. Let’s go!