
(date: 2024-12-15 07:05:12)
date: 2024-12-20, from: ETH Zurich, recently added
Llamas-Dios, Marta Inés; Jiménez-Gavilán, Pablo; Corada-Fernández, Carmen; Ojeda, Lucía; Jiménez-Martínez, Juan; Vadillo-Pérez, Iñaki
http://hdl.handle.net/20.500.11850/708431
date: 2024-12-14, from: Santa Clarita Public Library
Valencia Branch Temporary Closure FAQ The Valencia Library will be temporarily closed December 21, 2024 through January 1, 2025 for renovations. During this time, library staff will be providing a curbside service for patrons to pick up their holds. Please note that the Old Town Newhall Library and the Jo Anne Darcy Canyon Country Library […]
https://www.santaclaritalibrary.com/2024/12/13/valencia-branch-temporary-closure-faq/
date: 2024-12-13, from: Scholarly Kitchen
Last month, the Society for Scholarly Publishing (SSP) proudly launched the EPIC (Excellence in Publishing, Information Technology and Communications) Awards, celebrating outstanding achievements throughout our industry. This inaugural awards program recognizes the valuable work invested in accomplishments that help our […]
The post The Society for Scholarly Publishing Announces the EPIC Awards appeared first on The Scholarly Kitchen.
date: 2024-12-12, from: Standard Ebooks, new releaases
An Irish writer presents his vision of an independent Irish nation.
https://standardebooks.org/ebooks/george-william-russell/the-national-being
date: 2024-12-12, from: Standard Ebooks, new releaases
A collection of poems by Georgia Douglas Johnson.
https://standardebooks.org/ebooks/georgia-douglas-johnson/poetry
date: 2024-12-12, from: Standard Ebooks, new releaases
Twin brothers are found murdered in a maze, and the local Chief Constable must solve the crime.
https://standardebooks.org/ebooks/j-j-connington/murder-in-the-maze
date: 2024-12-12, from: Open Citation blog at Hypotheses.org
OpenCitations and the Barcelona Declaration are happy to announce that the call for participation and contributions to the Workshop on Open Citations and Open Scholarly Metadata 2025 is now open. After the success of the 2023 edition, this edition of the Workshop on Open Citations and Open Scholarly Metadata (WOOC) will take place in Bologna, on 28-29 May 2025. – https://workshop-oc.github.io. SCOPE We invite to WOOC researchers, scholarly publishers, funders, policymakers, institutions, and open citations advocates, interested in the widespread adoption of practises for … Continue reading Apply now to the Workshop on Open Citations and Open Scholarly Metadata 2025: the call for participation and contributions is open!
https://opencitations.hypotheses.org/3700
date: 2024-12-12, from: Association of Research Libraries News
Last Updated on December 13, 2024, 9:06 am ET Sign up to receive the Day in Review by email. Jump to: Thursday, December 12 | Wednesday, December 11 Top o’…
The post Day in Review (December 11–12) appeared first on Association of Research Libraries.
https://www.arl.org/day-in-review/day-in-review-december-11-12/
date: 2024-12-12, from: Scholarly Kitchen
A new survey looks at the philosophies and practices around librarian credentialing in the United States.
The post Guest Post: The Perennial Question of Librarian Credentialing appeared first on The Scholarly Kitchen.
date: 2024-12-12, from: Crossref Blog
Looking back over 2024, we wanted to reflect on where we are in meeting our goals, and report on the progress and plans that affect you - our community of 21,000 organisational members as well as the vast number of research initiatives and scientific bodies that rely on Crossref metadata.
In this post, we will give an update on our roadmap, including what is completed, underway, and up next, and a bit about what’s paused and why. We’ll describe how we have been making resourcing and prioritisation decisions, including a revised management structure, and introduce new cross-functional program groups to collectively take the work forward more effectively.

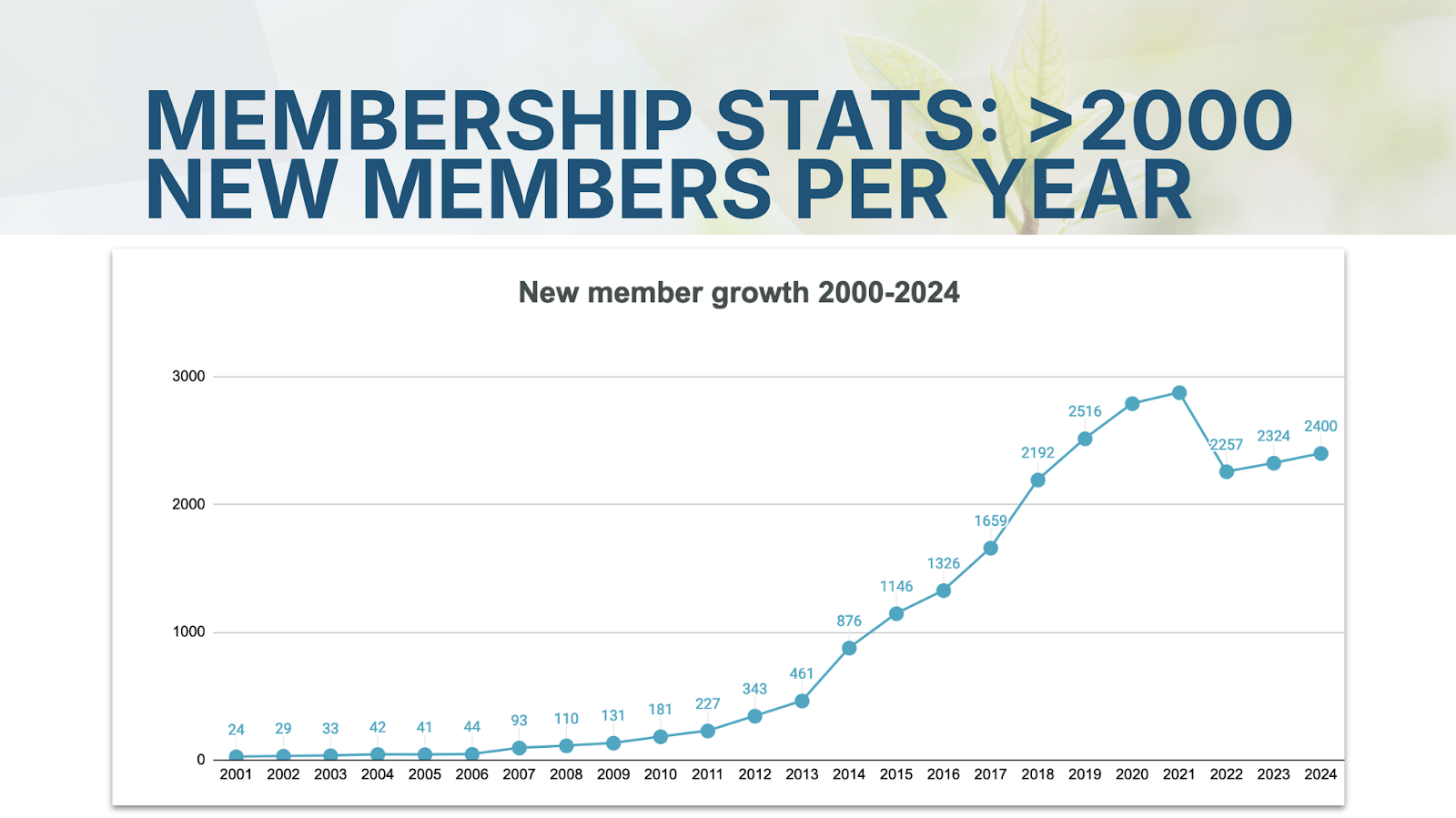
It’s important to acknowledge that Crossref has evolved significantly from just five years ago - our member count has more than doubled from 10,000 to 21,000 organisations since 2019 and they include all kinds of organisations such as funders, universities, government bodies, NGOs, and of course scholar- and library-led publishers. The smaller organisations now collectively contribute the majority of Crossref funding. We’ve gone from 100 million records to 160 million in five years, and our metadata is retrieved more than 2 billion times monthly, quadrupling what it was five years ago.
It’s within this context that we’ve spent quite a lot of time thinking about scalability, how we collect and process feedback and contributions from many organisations, how to automate our operations, and refining the plans for the next few years.

A few times a year we update the strategy page where there is a quadrant of projects showing what’s completed, in progress, up next, and in planning/ideas - for each strategic theme. We also link from there to our live public roadmap which shows more specifics about individual projects, including projected timelines, and is updated more frequently.
If you’ve been watching the strategy page, checking in on the public roadmap or this blog, or joining webinars and annual meetings, you’ll know that we’ve had some longstanding plans to—among other things—reduce technical debt, rebuild our metadata management system, move to the cloud, modernise our schema, support multiple languages, and partner with multiple data sources to build the Research Nexus.
You’ve heard us talk about these initiatives a lot, but you’ve not seen particularly swift action.
Earlier this year, it became clear that our almost three-year project to build a new relationships API had not worked out. The project, dubbed ‘manifold’, was to initially deliver data citations, and eventually replace our central metadata system, but what was prototyped didn’t scale, even with a subset of our metadata. We weren’t confident enough about the project’s timeline or costs to justifiably continue investing further time and resources.
Meanwhile, we’d barely scratched the surface of our aim to pay down technical and operational debt, and we’d also been neglecting to keep the live system up to date with the numerous metadata changes that have been queued up, waiting to be implemented.
We knew the manifold project was ambitious – our system has grown in complexity over the years. We were trying to rebuild the car while driving it (our system needed to continue to operate and be maintained by our team) while trying to design a new approach to manage the many relationships between 160+ million database records. In the years we worked on this project, we learned a lot that will inform future plans for a large system redesign.
In March this year, we decided to pause the manifold project. We apologised to our community partners for not delivering the promised data<->literature matches they hoped to use. They were frustrated but thankfully understanding.
We then resolved to focus on backend infrastructural changes, conduct cross-training so that all of our staff would become familiar with current in-use systems instead of greenfield tech (for now), and start to make a dent in the backlog of bugs and long-promised schema updates in our mainstream services.
We’re happy to report some movement on these things and some milestones that have been achieved in these areas in recent months.
Any kind of work can only happen when our staff are in a good place, feeling supported and comfortable to question things, and well-equipped with information, purpose, and clear priorities. In June, when the whole staff met up in person, we had some really good conversations about culture, communication, and about sharing responsibilities. Some people ran birds-of-a-feather sessions to explore the issues that had been keeping them up at night, such as authentication/security, and rebuilding the Crossref System (CS), and the team also co-created a set of prioritisation drivers that are now in use within our roadmap and planning processes.
Taking on feedback from the all-staff meeting and then the July board meeting, we thought strategically about the organisational structure Crossref would need over the next few years to reflect the growth in scope and size, and fulfil its longer term goals. We have long had an ambitious agenda but realised we didn’t yet have the capacity to do it all. So we came to the conclusion that we needed an updated team and management structure to take us through the next phase of our development.
The structural changes were concluded at the end of November. They included:
Unfortunately, with the shift in approach for product development and by sharing responsibility for strategic initiatives and research among the wider team, we made the difficult decision that four positions would no longer work within the new structure.
Research has always been an important role for Crossref, but as this function had been annexed from our regular work, it became hard to coordinate strategic initiatives across the wider organisation. In recent years we inadvertently created more technical debt for ourselves, i.e., built multiple prototype tools without plans for adoption or moving them into production. Strategic initiatives, by their nature, need thorough research and high-level alignment, so we made such initiatives—things like Resourcing Crossref for Future Sustainability (RCFS) and improving the Integrity of the Scholarly record (ISR)—the responsibility of the whole senior management team.
Some useful research had been conducted, but we were never in a position to act on any of it. Particularly promising work has been in the field of metadata matching, and with the growth in the community reliance on our metadata, and attention on data quality rightly increasing, we decided to create a new data science team to be dedicated to this work, led by Dominika Tkaczyk.
We had also struggled with a traditional product management approach since all our tools and activities are interconnected, and we found we were trying to do too many things at once but not all of them very effectively. We also acknowledged that product management comes from the commercial e.g. retail world and therefore is designed to help companies sell/upsell, which is not our goal. So we looked to other approaches more suitable to mission-based nonprofits.
We have introduced cross-functional program management in order to work towards the following:
Supporting the strategic theme of co-creation, a new program, facilitated by Program Lead Lena Stoll, now manages and oversees all activities around co-creation and community trends. A cross-team steering group just began meeting regularly and will be responsible for interfaces such as reports/dashboards, record registration interfaces, connections and collaborations such as Open Funder Registry, ROR, ORCID auto-update, as well as OJS and other partner integrations. This program also includes the Crossref website and any front-end things to support other programs. And it includes ISR (the integrity of the scholarly record) and our tools in this area such as Crossmark and retraction/correction tooling, and Similarity Check for text comparisons.
Supporting the strategic theme of complete and global metadata and relationships, a new program, facilitated by Program Lead Martyn Rittman, now manages and oversees all activities relating to contributing to the Research Nexus. Working particularly closely with the metadata team, led by Patricia Feeney, this program addresses how metadata is modelled, used, enriched, and extended. Work includes our APIs, incorporating external data sources like Retraction Watch and Event Data, building out metadata matching services with the new data science team, supporting the community of metadata users with API sprints and more modern options for retrieving metadata based on usage and need.
Supporting the strategic theme of open and sustainable operations and keeping to the POSI framework, a new program, facilitated by Program Lead Sara Bowman, now manages and oversees all activities relating to making our operations more open, transparent, and sustainable. This program focuses on supporting and strengthening the core functions our members rely on and enabling future growth. It includes metadata deposit and processing, most apps for e.g. managing titles, authentication, and architectural and infrastructural projects like moving from the data centre to the AWS cloud service. This program also includes modernising our operations in general, which is not just technology but also finance and human resources, so projects like membership process automation, fee modelling and financial analyses, and business system integrations.
The Programs will start to be reflected across our website and in our communications from next year.
These are the drivers that our ~40 staff co-created in June that are guiding decisions about the priorities on our roadmap. New ideas will be evaluated in the following areas:
We’re happy to report that the changes made this year have resulted in a productive last few months of the year. As reported in our annual meeting, here is the progress update.
Since the rest of the community stops for no Crossref product roadmap issue, we also progressed a number of community and governance initiatives:
In our efforts to do less but do it more effectively, we have two current priorities:
These two projects are underway, involving lots of communication and learning. Since we haven’t released any schema updates in many years, all our staff are learning for the first time how a metadata schema model is interpreted in a systemic way, learning about the structure of research objects, and honing the process as they go. We’ve high hopes we’ll be in a position to release continuous metadata schema versions and catch up on the backlog over the coming years.
Once we’re fully in the cloud and in the groove of metadata updates, and with the support of newly-hired technology and program directors joining in the new year, we’ll turn our attention to rebuilding the central metadata system that we call the Crossref System, or “CS” and report more on this next year.
So that was our summary of 2024 and an indication of what’s coming in 2025 and beyond; sorry it’s so long, and thanks for reading this far! Next year we’ll get back to more regular updates as the strategic agenda and the programs progress.
https://www.crossref.org/blog/a-progress-update-and-a-renewed-commitment-to-community/
date: 2024-12-11, from: Internet Archive Blog
The following guest post from media historian Taylor Cole Miller is part of our Vanishing Culture series, highlighting the power and importance of preservation in our digital age. Read more essays online or download the full […]
date: 2024-12-11, from: Scholarly Kitchen
A relentless push for growth can lead to burnout among authors, editors, and reviewers, while also placing undue pressure on organizations to maintain high levels of output. How can we better provide the infrastructure and support systems needed to sustain that growth over the long term.
The post Growth Without Burnout: Managing Polarities Consciously for Sustainable Success in Publishing appeared first on The Scholarly Kitchen.
date: 2024-12-10, from: Standard Ebooks, new releaases
A collection of poems by Thomas Gray.
https://standardebooks.org/ebooks/thomas-gray/poetry
date: 2024-12-10, from: Standard Ebooks, new releaases
A king tries to save his citizens from a devastating plague.
https://standardebooks.org/ebooks/sophocles/oedipus-rex/francis-storr
date: 2024-12-10, from: Standard Ebooks, new releaases
A woman in an unhappy marriage finds love with the local gameskeeper, while she contemplates her position in the society of early 20th century England.
https://standardebooks.org/ebooks/d-h-lawrence/lady-chatterleys-lover
date: 2024-12-10, from: Association of Research Libraries News
Globally, less than 10% of all published material is accessible to people with visual disabilities according to the World Blind Union. The Marrakesh Treaty to Facilitate Access to Published Works…
The post ARL and CARL Celebrate Human Rights Day with Resources on Marrakesh Treaty and Accessible Books Consortium appeared first on Association of Research Libraries.
date: 2024-12-10, from: Scholarly Kitchen
India’s recently announced One Nation, One Subscription plan is in some ways an audacious step into the future and, in other ways, an embrace of the past. What are its implications?
The post Chatting at the Kitchen Table about India’s ONOS Deal appeared first on The Scholarly Kitchen.
https://scholarlykitchen.sspnet.org/2024/12/10/chatting-at-the-kitchen-table-about-indias-onos-deal/
date: 2024-12-09, from: Standard Ebooks, new releaases
A young girl’s emotional hurt requires time and love to heal.
https://standardebooks.org/ebooks/johanna-spyri/cornelli/elisabeth-p-stork
date: 2024-12-09, from: Standard Ebooks, new releaases
A fire that leaves three dead has enough hints of murder to draw our detective up to Yorkshire.
https://standardebooks.org/ebooks/freeman-wills-crofts/the-starvel-hollow-tragedy
date: 2024-12-09, from: Standard Ebooks, new releaases
The story of a young woman who marries badly, told in several vignettes covering the remainder of her life.
https://standardebooks.org/ebooks/honore-de-balzac/a-woman-of-thirty/ellen-marriage
date: 2024-12-09, from: Scholarly Kitchen
Without understanding the dimensions of ethics in scholarly communications, our attempts at improving the system through tools and training may not be effective and sustainable.
The post Ethics In Scholarly Publishing Is More Than Following Guidelines appeared first on The Scholarly Kitchen.
date: 2024-12-09, from: Crossref Blog
The Crossref2024 annual meeting gathered our community for a packed agenda of updates, demos, and lively discussions on advancing our shared goals. The day was filled with insights and energy, from practical demos of Crossref’s latest API features to community reflections on the Research Nexus initiative and the Board elections.

Our Board elections are always the focal point of the Annual Meeting. We want to start reflecting on the day by congratulating our newly elected board members: Katharina Rieck from Austrian Science Fund (FWF), Lisa Schiff from California Digital Library, Aaron Wood from American Psychological Association, and Amanda Ward from Taylor and Francis, who will officially join (and re-join) in January 2025. Their diverse expertise and perspectives will undoubtedly bring fresh insights to Crossref’s ongoing mission.
The meeting started with a recap of our mission and priorities. Ed Pentz reiterated the Research Nexus vision of increasing transparency of the connections that make up the scholarly record and underpin the research ecosystem.
Crossref is dedicated to openness, community ownership, and a stable, accessible infrastructure that researchers, publishers, funders, and institutions can rely on for the long term. This is demonstrated by Crossref’s commitment to the the Principles of Open Scholarly Infrastructure (POSI), which constitute commitments to building a resilient and transparent infrastructure for research—sustainability, community governance, and openness. Ed emphasized how Crossref is aligning with these principles and collaborates with other adopters to reflect and continuously align these with the needs of the scholarly community, with a public consultation on proposed revisions to POSI forthcoming next year.
Ginny Hendricks highlighted key membership and metadata trends. She noted that as of 2024, half of Crossref members are based in Asia. This year, as always in recent years, we saw many new organizations from Indonesia, Turkey, India, and Brazil join us. Removing those fast-growing countries for the chart’s clarity, we can see that some of the next most active countries are Pakistan, Mexico, Spain, Bangladesh, and Ecuador, among others.
There are now ~163 million open metadata records with Crossref DOIs, and Ginny pointed out increases in the registration of preprints, peer-review reports, and grants. In terms of metadata elements, it’s good to see that more publishers recognize the importance of including abstracts and ROR IDs in their metadata records. Also, in line with the community’s concerns about integrity, our members have been enriching their records with direct assertions of retractions.
Then, Ginny went on to report on the progress towards our strategic goals:
Lena Stoll and Patrick Vale’s session gave members a practical preview of our latest tools.
Patrick started by reflecting on the challenge of making our identifiers useful for people using screen readers (and other assistive technologies). He thanked all who responded to our past consultation on the topic and presented the Crossref DOI Accessibility Enhancer – the browser plug-in initially available for Firefox (and soon also for Chrome). He shared the Gitlab repo for anyone interested in trying it and invited feedback as we’re hoping to iterate on this.
Patrick then went on to talk about our openness to community contributions to Crossref tools, with an example of the recent contribution from CWTS Leiden to our Participation Reports. Thanks to their work, our members can now see the proportion of works they’ve registered that include affiliation information and ROR IDs, alongside the previously available key metadata such as references, abstracts, ORCID iDs, funding information, or Crossmark.
Finally, Lena demonstrated the latest extension of our record management tool that’s just been made available to make manual registration of metadata records for journal articles easier. The new form is flexible and driven by our metadata schema. Importantly for our members, it simplifies the workflow with input validations and automated ISSN matching, and it enables members to register author affiliations with an integrated ROR look-up. We hope this will support our smaller members, who are relying on our helper tools to register their content.
Throughout the session, members were encouraged to use these tools and explore new resources available through Crossref. We believe that by taking advantage of these resources, you can enhance your research and publishing experience, and contribute to the growth and development of the scholarly community.
The panel on open scholarly infrastructure brought together experts with a wide range of experience in the field. Moderated by Lucy Ofiesh, Crossref’s Chief Operating Officer, the discussion featured six invited speakers who shared their insights on the opportunities and challenges facing the scholarly ecosystem: Ed Pentz, Crossref; Sarah Lippincott, Dryad; Amélie Church, Sorbonne University; Joanna Ball, DOAJ; Ann Li, Airiti; and Richard Bruce Lamptey, Kwame Nkrumah University of Science and Technology.
The panel talked about what openness in scholarly infrastructure means, why it’s important, its sustainability, and how to tackle challenges and gaps across the ecosystem. They highlighted frameworks like the Principles of Open Scholarly Infrastructure (POSI), the Barcelona Declaration, and the FOREST Framework as key tools for guiding work on governance, sustainability, and equity. The discussion highlighted the need for more collaboration, inclusivity, and practical ways to ensure open infrastructure remains sustainable in the long run.
They also stressed how openness supports research integrity. How transparent systems allow researchers to question methods, verify findings, and preserve data. Amelie Church expanded on this point, underscoring the important role of open infrastructure in addressing challenges to integrity. She explained that such transparency enables the scholarly community to scrutinize research processes, ensuring the quality of outputs and their impact on society. Without openness, researchers face barriers to maintaining trust in their work, making open infrastructure necessary for research integrity and public confidence in science.
“By focusing on accessibility, transparency, and community engagement, open infrastructure can reshape academic and research ecosystems in transformative ways.” ~Richard Bruce Lamptey
Regarding sustainability, Sarah Lippincott stressed the importance of aligning funding models with community needs while addressing governance challenges. She pointed out that while initial funding can launch infrastructure, long-term sustainability requires consistent community investment and robust governance frameworks. This balance, she explained, is essential to ensure equity and transparency.
Collaboration was another important topic. Joanna Ball and Sarah Lippincott shared examples of how pooling expertise and resources—such as in the global support for ROR—can strengthen systems and make them more sustainable. These initiatives show the power of collective efforts in addressing technical and resource barriers. However, inclusivity remains an ongoing challenge.
The panel discussed the ways in which language barriers, resource limitations, and reliance on proprietary systems continue to exclude researchers from underrepresented regions. Ann Li highlighted how addressing these disparities is critical to ensuring the global accessibility of open infrastructure. By fostering inclusive practices, the scholarly community can mitigate biases and build tools that reflect a broader range of research contributions.
”My hope is that open infrastructure can have the resources that it needs to thrive, not just merely survive, and also that open infrastructure communities and organizations look to the value of frameworks that we’ve talked about today to help align themselves and improve their policies and practices, because there’s always room for growth, even in the best, most well-intentioned communities.” ~Sarah Lippincott, Dryad
The panel wrapped up the discussion by expressing optimism for the future of open scholarly infrastructure and emphasized the importance of continued investment, collaboration across organizations, and transparency in operations. The discussion reinforced the idea that open infrastructure provides a strong foundation for research that is equitable, sustainable, and accessible to all.
We enjoyed talks from our community about increasing their participation in the Research Nexus by adopting, using and enhancing metadata in different ways. Robbykha Rosalien hosted talks from the EuropePMC, Dutch Research Council, eLife, and CSIRO featured in Session I, and Amanda French hosted CLOCKSS, Sciety, and Redalyc in Session II.
Michael Parkin talked about preprints in Europe PMC. Europe PMC is a database for life science literature and a platform for content-based innovation. They started indexing preprints via Crossref REST API in 2018. Michael presented their work on discoverability of preprints in their database, including reflections on early challenges, as well as the latest efforts in surfacing available community reviews.
Hans de Jonge talked about the Dutch Research Council’s (NWO) dedication to open science, with policies ensuring that publications and data funded by NWO are openly available. They embrace open science principles for their own metadata and is a signatory of the Barcelona Declaration on Open Research Information. Hans focused on NWO’s recent introduction of Grant IDs through Crossref’s Grant Linking System (GLS). He shared their approach, the motivations behind introducing Grant IDs, and some challenges they faced.
Frederick Atherden explained how eLife, a nonprofit led by scientists, use Crossref’s Grant Linking System to include grant DOIs in their publication metadata. It allows authors to add grant DOIs during submission, and they developed a tool to match grant numbers with DOIs during the proofing process to improve accuracy. Their goal is to follow best practices for metadata, making content easier to find and link to.
Brietta Pike covered how CSIRO is working to improve metadata quality for its journals, making research more discoverable and trustworthy. CSIRO faced challenges like inconsistent XML tagging, outdated systems, and data loss. To address these, they formed a project team, created a clear XML stylesheet, and updated their workflows. Recent progress includes better funding data, clearer license information, and more complete affiliation tagging. These efforts aim to support a more transparent and accessible research environment.
Alicia Wise of CLOCKSS talked about recent collaborations seeking to safeguard our cultural and scholarly heritage over the long term. CLOCKSS, a community-run archive, is dedicated to preserving scholarly content to remain accessible and unchanged for future generations. True preservation requires securely storing content in trusted archives that are actively maintained. A group of librarians and publishers developed a guide to help publishers preserve content, they also established an archival standard for EPUB formats to ensure ebooks can be stored effectively, and launched a pilot project to track preserved books, helping libraries and scholars identify safely stored titles.
Mark Williams from Sciety talked about how Sciety uses Crossref metadata to create detailed preprint histories. By partnering with organizations and communities worldwide, Sciety platform gathers public reviews, highlights, and recommendations on preprinted research, helping researchers evaluate the quality and relevance of new studies. Through linking related preprints and journal articles, Sciety builds a connected view of each research work. Although challenges like inconsistent terminology and identifier gaps persist, these efforts enhance the visibility and credibility of preprints.
Arianna Becerril-García of AmeliCA/Redalyc shared insights on diamond open-access journals in Latin America. Redalyc is an open-access infrastructure that supports journals by providing free services like visibility and production tools. Redalyc has a role in sustaining Latin America’s unique approach to open-access publishing, where most journals are backed by academic institutions and public funds, allowing free access for both readers and authors. Arianna stressed the need to treat these journals as digital public goods and urged the communities they serve to help ensure their long-term sustainability. Despite limited resources and global under-recognition, these journals serve an international research audience, including authors from Europe, Africa, and Asia. Redalyc and other open infrastructures play a key role by offering tools that reduce production costs and improve discoverability, all without financial barriers. Noted was how this approach aligns with UNESCO’s open science framework, which promotes inclusivity and addresses long-standing inequalities in scholarly publishing.
After a mid-day break (in Europe), Luis Montilla kicked off the second session with a practical tutorial of Crossref’s REST API. Following his last year’s intro to the Crossref API, this time he offered a step-by-step guide to help attendees maximize the API’s capabilities for metadata retrieval with advice on:
For those interested in learning more, look at the new Crossref API Learning Hub— a new resource offering guides, scripts, and training materials to simplify complex queries. Please share questions about things you’re not sure about in our community forum, to help guide development of future demos.
Patricia Feeney followed with updates on metadata schema changes. She introduced our recent shift to integrate the Funder Registry with ROR, which allows members to use a single identifier system, simplifying data management by reducing redundancy. Patricia explained that, for now, the current identifiers remain valid, so members won’t need to make immediate changes. She also outlined planned support for version metadata, typed citations, and future plans to expand support for contributor role vocabularies, and invited community participation in a planned multilingual metadata working group.

Next, Kora Korzec offered an update on the progress in our research on Resourcing Crossref for Future Sustainability and opened up a discussion about the best ways of assessing our members’ size and ability to pay. In light of our ambition to streamline discounts, we also invited suggestions for discounts to support accessibility and fuller participation in the Research Nexus.
As part of the discussion, we’ve learned who was in attendance during the session:
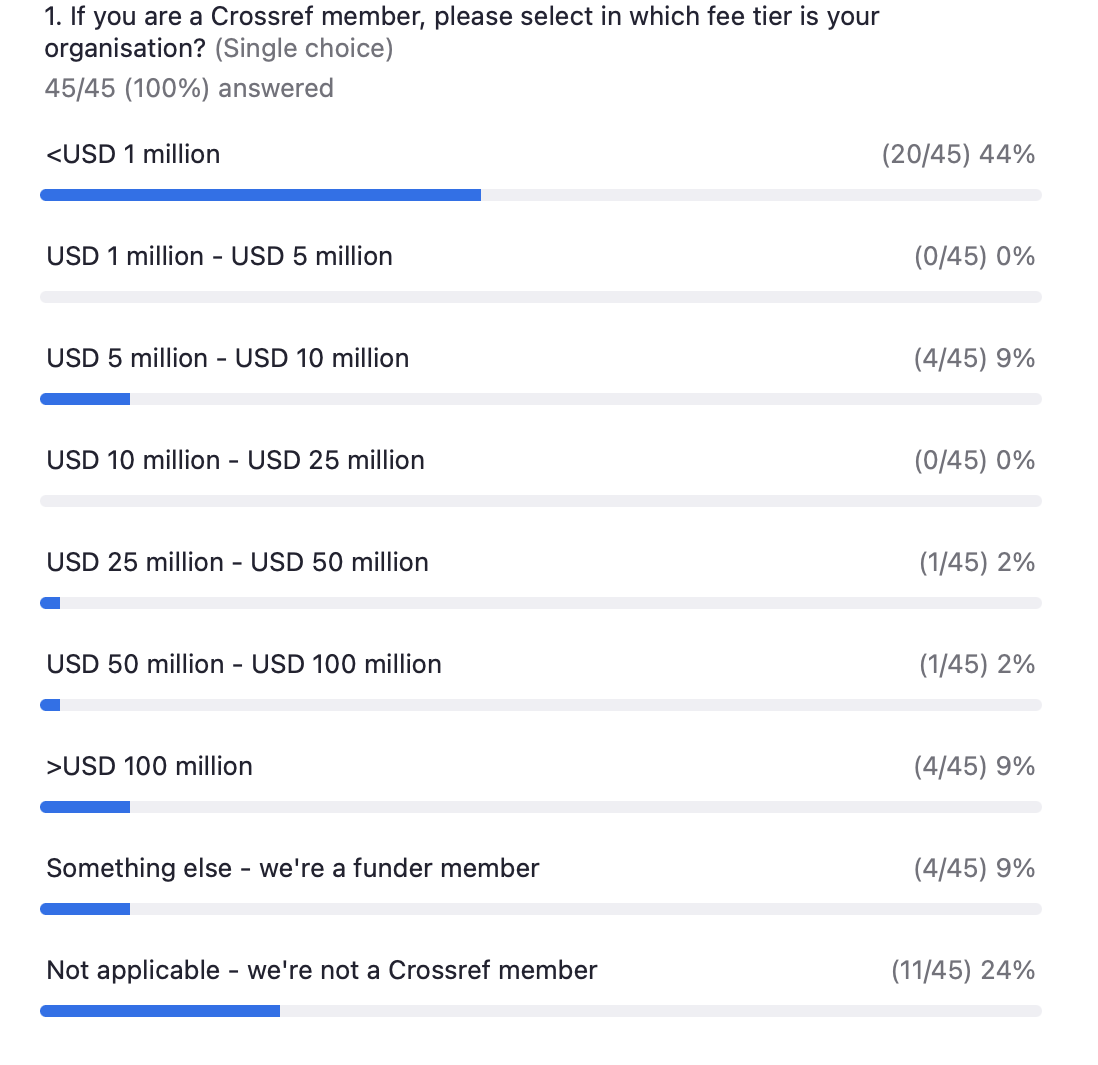
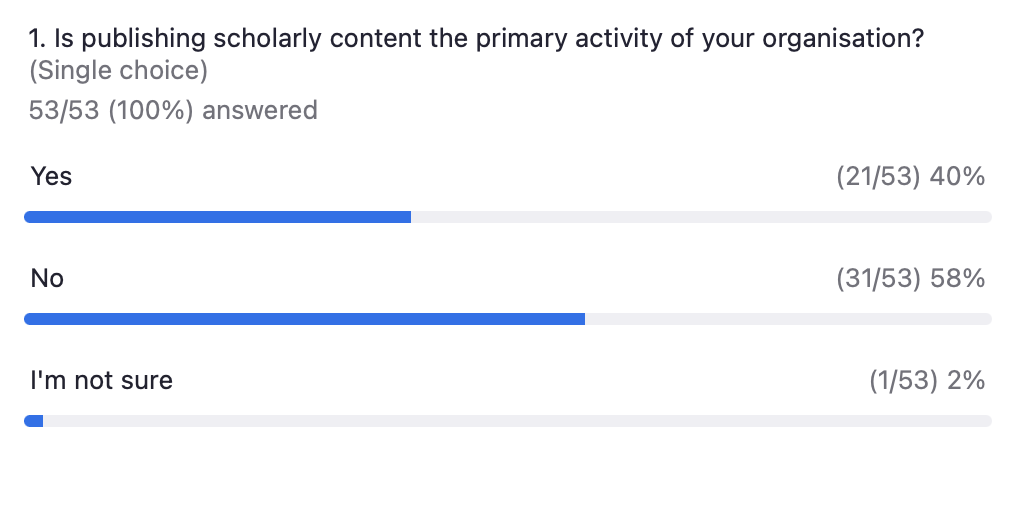
We’ve heard a lot of support for our current GEM program. While it was clear from our poll that publishing revenue is not the most relevant measure of size or capacity for all those present – establishing a good alternative proved challenging. The idea of considering the size of the organization as its largest entity has been discussed, and important points were raised about budgets in different types of distributed organizations (e.g., on the position of libraries within large universities).
The official Annual Meeting part commenced after the discussion, with a report on the State of Crossref from Lucy Ofiesh, and commenced with our Board election. Lucy highlighted some of the key accomplishments of the year so far, including:
Then she reflected on the membership growth––Crossref is now made up of 21,000 organizations from 160 countries. We reviewed our 2024 year-end financial forecast. As we’re bouncing back from COVID-19, our travel expenses have grown this year, and so have the fees for cloud services hosting. These are all as planned and happen in the context of healthy growth, including that from adoption and increased usage of paid services. We’re in a healthy financial position as membership revenue and usage fees, like content registration and Similarity Check document checking fees, continue to grow from the previous year.
Thank you to everyone who joined us for Crossref2024. This year’s meeting showcased our collective dedication to advancing open, accessible research infrastructure and underscored the power of collaboration in building a stronger scholarly community. As we reflect on the rich discussions and insights shared during the event, it’s clear our community is committed to advancing open and sustainable scholarly infrastructure.
Looking ahead, we’ll continue collaborating with members and partners to tackle challenges, expand accessibility, and foster collaboration. A key focus will be enhancing tools and metadata standards to serve the community better. Through innovative solutions and strategic initiatives like the Research Nexus, our collective efforts will make research more connected and accessible for all.
For anyone who couldn’t attend live, recordings are now available on our website. We’re excited to see how the ideas exchanged during this meeting spark progress across the scholarly ecosystem in the coming months.
https://www.crossref.org/blog/a-summary-of-our-annual-meeting/