
Sixteen-year-old Simone O. Elias has a lot to say about her generation and the way it is perceived by society. Rather than wait for a traditional publisher, the Berkeley, California, […]
The Archive Becomes Infrastructure — But It Doesn’t Stop Being Memory
China’s new Five-Year Plan for archives reads like a blueprint for digital government. The more consequential question is who gets to write the standards underneath it.
Mental Health Awareness Mondays: Community Through Communication — An “I AM EDITOR” Spotlight
, updated:
This post is part of a special collaboration between The Scholarly Kitchen's Mental Health Mondays and EON's I AM EDITOR. United by a shared commitment to the people who have been called to scholarly publishing, this partnership seeks to amplify conversations about mental health, reduce stigma, and nurture a more supportive, resilient, and connected professional community.
The post Mental Health Awareness Mondays: Community Through Communication — An “I AM EDITOR” Spotlight appeared first on The Scholarly Kitchen.
TechCrunch: “Librarians are Hosting Viral ‘Avoiding AI’ Workshops For People Who are Fed Up With Big Tech”
From TechCrunch: [Charlie] Bailey [a librarian in South Philadelphia, PA] stands at the front of a library classroom that’s outfitted for children – the focal point is the vibrant rug he’s standing on, which reminds us that M is for “moon” and Z is for “zebra.” But the 20-odd adults in the room aren’t here […]
The post TechCrunch: “Librarians are Hosting Viral ‘Avoiding AI’ Workshops For People Who are Fed Up With Big Tech” appeared first on Library Journal infoDOCKET.
Custody Without Possession
, updated:
ERA, Data at Rest, and the Question NARA Didn’t Answer
New Journal Article: “Personal Data Privacy Literacy and Library Privacy Awareness and Concern Among Academic Library Employees”
, updated:
The article linked below was published by The Journal of Academic Librarianship. Title Data Privacy Literacy and Library Privacy Awareness and Concern Among Academic Library Employees Authors Bryan Anderson University of North Texas Brady D. Lund University of North Texas Yara Mohammed University of North Texas Zafar Imam Khan Hamdan Bin Mohammed Smart University, Dubai, […]
The post New Journal Article: “Personal Data Privacy Literacy and Library Privacy Awareness and Concern Among Academic Library Employees” appeared first on Library Journal infoDOCKET.
The Future of the Scientific Article in the Age of AI
The current model of scientific publishing has ceased to be a means of producing scientific articles and communicating discoveries and has instead become a tool for bureaucratic exchange aimed at promoting individuals and/or institutions.
By measuring a scientist’s value by the volume of their publications rather than the rigor of their data, the system has created the perfect conditions for vulnerability, allowing AI-driven automation to trigger a crisis of editorial overproduction and jeopardize the credibility of science itself.
The post The Future of the Scientific Article in the Age of AI first appeared on SciELO in Perspective.
International Federation of Library Associations and Institutions (IFLA) Releases 2025 Annual Report
, updated:
From an IFLA Post: The 2025 edition covers the first full year of our 2024–29 Strategy and is structured around its three Impact Areas as well as our work to future-proof the Federation. Overall, 2025 shows ongoing progress: stronger connections, more impactful advocacy, deeper investment in capacity and futures, and a sharper focus on sustainability. [Clip] Some highlights […]
The post International Federation of Library Associations and Institutions (IFLA) Releases 2025 Annual Report appeared first on Library Journal infoDOCKET.
Friday Food for Thought: Surviving the Cyclospora Outbreak
, updated:
Today, The Scholarly Kitchen brings you literal cooking tips -- recipes and advice for your weekend menus!
The post Friday Food for Thought: Surviving the Cyclospora Outbreak appeared first on The Scholarly Kitchen.
Journal Article: “Understanding Generative AI-Mediated User Engagement with Academic Library Resources”
, updated:
The article linked below is a preprint (accepted manuscript) of a paper that will be published in the May 2027 issue of College & Research Libraries. Title Understanding Generative AI-Mediated User Engagement with Academic Library Resources Authors Hae Min Kim Drexel University Stacy Stanislaw Drexel University Source via arXiv Forthcoming: College & Research Libraries DOI: […]
The post Journal Article: “Understanding Generative AI-Mediated User Engagement with Academic Library Resources” appeared first on Library Journal infoDOCKET.
Advocating for Digital Accessibility: An Interview with Junior Fellow Mia Giancola
, updated:
In this interview, 2026 Library of Congress Junior Fellow Mia Giancola discusses working on the Year of Digital Accessibility in the Library’s IT Design & Development Directorate. This interview has been edited for length and clarity. Pedro: It’s great to have you on our team this summer. Could you tell us what you are working …
Guest Post — Why Research Expectations Have Outpaced the Systems That Enabled Them (Part 2)
, updated:
Today's post is the second in a series arguing that fractures appearing across research systems are symptoms of a mismatch within today's research ecosystem.
The post Guest Post — Why Research Expectations Have Outpaced the Systems That Enabled Them (Part 2) appeared first on The Scholarly Kitchen.
Consumers Are Worried About the Loss of Physical Media Ownership. Libraries Are Leading the Conversation.
Last Updated on July 22, 2026, 3:09 pm ET Sally Sax is head, Collection Strategy and Partnerships, MacOdrum Library, Carleton University. In a recent Atlantic Monthly article about Sony’s plan...
The post Consumers Are Worried About the Loss of Physical Media Ownership. Libraries Are Leading the Conversation. appeared first on Association of Research Libraries.
Bringing Forgotten Music Back to Life with Optical Music Recognition
, updated:
Just as printed letters can be scanned and converted into digital text, emerging technology can transform sheet music into sound. A new effort is underway to use optical music recognition […]
How AI Is Reshaping the Value of Higher Education
AI touches all of the basic assumptions that underlie how we think about the value of postsecondary education and academic research: what students need to learn, how they learn, how institutions operate, and how universities contribute to the production and dissemination of knowledge. The immediate questions it raises are urgent and real. Students need AI […]
The post How AI Is Reshaping the Value of Higher Education appeared first on Ithaka S+R.
Understanding the CORE Dashboard: Checking Open Access Compliance for REF2029
With this instalment of our educational series we begin exploring the OA Compliance tab in the CORE Dashboard. Over the next three instalments we will look at the different compliance views the Dashboard offers: REF2029, the RIOXX metadata validator, and the Desirable Characteristics Report. We start with REF2029. What the REF2029 tab does The REF2029 … Continue reading Understanding the CORE Dashboard: Checking Open Access Compliance for REF2029
Vanishing Culture Episode #4: Keeping African Folktales Alive with Helen Nde & Laura Gibbs
, updated:
Folktales are more than stories—they are living records of culture, identity, and collective memory. In the fourth episode of our special six-part series on Vanishing Culture, host Vida Vojić speaks […]
When LLMs Can Argue Both Sides Better Than You Can
, updated:
Can Teaching Media Literacy Backfire in the Age of LLMs? Revisiting Boyd’s 2017 provocation
Authenticity Is Not a Deliverable
, updated:
US Patent 7,792,791 B2 and the limits of building trust into a system
Guest Post — What Does Commercial Adoption Mean for the Preprint Movement?
, updated:
Today's guest bloggers suggest that the involvement of commercial publishers is not unequivocally bad for preprints, and provide some optimism about open access as a whole.
The post Guest Post — What Does Commercial Adoption Mean for the Preprint Movement? appeared first on The Scholarly Kitchen.
“You Just Never Know How You’re Having an Impact”: Irene Herold Reflects on Her Career and the Profession
, updated:
Last Updated on July 21, 2026, 12:42 pm ET Irene Herold is retiring on August 1 as dean of libraries and university librarian at Virginia Commonwealth University (VCU) after a...
The post “You Just Never Know How You’re Having an Impact”: Irene Herold Reflects on Her Career and the Profession appeared first on Association of Research Libraries.
Transcription Can Bring People Together: A Reflection from Shelby Kruger
, updated:
In this blog post, 2026 Junior Fellow Shelby Kruger reflects on her work with the By the People crowdsourced transcription program this summer.
Charting a sustainable future for TDCC-NES
, updated:
IOI is partnering with TDCC-NES, a collaborative network across the Dutch natural and engineering sciences domain that addresses FAIR data and other digital-related research challenges, to co-develop a post-NWO sustainability and co-investment model with its community.
How Bangladesh Is Reducing The North-South Divide In Scholarly Publishing
, updated:
Four Bangladeshi academics touch upon different aspects of academic publishing by linking them with the SDGs: accessing research; equity in co-authorship; editorial leadership; and SDG framing.
The post How Bangladesh Is Reducing The North-South Divide In Scholarly Publishing appeared first on The Scholarly Kitchen.
ARL Daily Intelligence (July 20–22)
, updated:
Last Updated on July 22, 2026, 3:39 pm ET The ARL Daily Intelligence is the trusted source of news and analysis for library leaders and advocates. Released Monday through Thursday, the ARL Daily...
The post ARL Daily Intelligence (July 20–22) appeared first on Association of Research Libraries.
The Architecture of a Missed Opportunity
, updated:
How early warnings about NARA's Electronic Records Archives anticipated problems that later audits would rediscover
Guest Post — Why Research Expectations Have Outpaced the Systems That Enabled Them (Part 1)
, updated:
Today's guest blogger questions the operating model around scholarly research and asks why these capabilities are so difficult to sustain at scale.
The post Guest Post — Why Research Expectations Have Outpaced the Systems That Enabled Them (Part 1) appeared first on The Scholarly Kitchen.
Why PID strategies need more than PIDs: our first position paper
PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Why now? The world looks very different from when Crossref was set up, and what we steward now reaches well beyond our membership: open metadata flows into national assessment systems, discovery services, integrity tools, and the AI systems learning from the scholarly record. Increasingly, decisions about research infrastructure are made by people who have never registered a record with us. Setting out our positions in public on key issues—to be referenced for years to come—seems a useful way to take that wider responsibility seriously.
The central argument of this paper is that decisions about PIDs are often framed as a choice of identifier, whereas what is really being chosen is infrastructure. Identifiers alone—however well-designed—cannot deliver the connected, open record that researchers, institutions, funders, publishers, and policymakers depend on. Effective research infrastructure rests on three interdependent elements: open, persistent identifiers; rich, open, and linked metadata; and the sustainable governance and operation of the organisations involved.
We urge those developing PID strategies and open science policies to evaluate all three together, looking beyond the identifier itself to the metadata, services, interoperability, and long-term sustainability that provide the real-world value they seek.
One thing the paper is clear about: not all DOIs are equivalent, and there is no centralised DOI metadata store—meaning a policy that specifies ‘use DOIs’ without accompanying requirements for metadata, services, and governance, can leave important questions open. We therefore recommend that policies spell out the real-world outcomes needed, not just the identifier type.
The paper is also explicit about what persistence actually takes. Real persistence is active: a social contract in which members take on the long-term stewardship of their own records. And it has to be paid for; infrastructure serving the record in perpetuity should demonstrate financial resilience. The paper shows how Crossref delivers both: our members actively maintain their records, and our membership model has kept us financially resilient for the long term while also paying it forward and supporting others.
The paper also addresses digital sovereignty, a live concern in many national strategies. Our answer is that sovereignty is safeguarded by design, not just by trust. National institutions are not customers of this infrastructure; they are members and governors of it, they remain the authoritative source of their own metadata, and their investment strengthens the shared record rather than fragmenting it.
Who is this paper for?
Policy strategists get the macro view: why identifiers, metadata, and governance need to be evaluated together, and how infrastructure choices shape the long-term success of a research strategy.
Decision-makers get criteria to require before a decision is made: how to evaluate PID infrastructure as a whole, including interoperability, sustainability, and governance.
Practitioners get a view of what good implementation looks like before committing: practical requirements for the metadata and services that make an identifier system useful in daily operation.
Key positions
-
PIDs are a means to an end. The value of an identifier system lies in the richness of its associated metadata, the scalability of the services it enables, and the needs it meets for the communities it serves.
-
PIDs can be complementary rather than competitive. Research uses many identifier types; they coexist productively, each serving the community and use case for which they were designed.
-
Not all DOIs are equivalent. Different DOI Registration Agencies offer fundamentally different services, metadata, and governance. Concrete requirements and expected outcomes for each entity being identified—not just identifier type—are therefore essential in any policy or implementation.
-
Interoperability is critical. Implementing identifier systems without evaluating their interoperability undermines the goal of a connected research record. National strategies must ensure that proposed PID infrastructure connects to the broader global research ecosystem.
-
Sustainability and governance matter as much as technical standards. Community governance and demonstrated financial resilience should be taken into account in any assessment of infrastructure organisations.
-
Open infrastructure—not PID adoption alone—is the foundation of a connected, open research record. Strategies should measure success based on the openness, connectivity, and reach of the surrounding infrastructure and its services.
Join the conversation
The paper includes worked examples from the UK, Portugal, Canada, and South Africa—policies that specify needs and outcomes rather than prescribing identifier systems, which is what we think good PID strategy looks like in practice. If you’re developing or reviewing research infrastructure policy and want to talk it through, we’d welcome that. Start a discussion on our community forum, or email us via feedback@crossref.org anytime. This paper is also the newest addition to our publications area, which gathers 25 years of Crossref reports, guides, and perspectives in one place.
Cite the paper as: Crossref (2026). Persistent identifiers in research infrastructure policy: the need for a holistic approach. Crossref Position Paper. https://doi.org/10.13003/q4vu-l2mw
AI Search Is Rebundling Everything Libraries Know About Discovery
, updated:
Ten established traditions, an emerging eleventh, and why libraries need to have a more holistic view of discovery
Keeping Knowledge Accessible Starts Here: Subscribe to the Empowering Libraries Newsletter.
, updated:
Every day, information professionals at libraries, archives, museums and research organizations all over the world work to ensure that knowledge remains available for future generations. From preserving websites before they […]
New Online at the Library of Congress: July 2026
, updated:
In our July 2026 edition of "What’s New Online at the Library of Congress," we share updates to the Library's digital collections, volunteer transcriptions, datasets, and more. Click through for more!
The Records the National Archives Can't Account For
, updated:
Fifteen years of audits reveal not one problem, but three: records that never arrived, records that cannot yet be processed, and records the public has no way to see are missing.
The Latest Merger: Annual Reviews Acquires Underline Science
, updated:
Annual Reviews have been on a steady growth trajectory these last few years, so we sat down with Richard Gallagher to learn more about their latest acquisition.
The post The Latest Merger: Annual Reviews Acquires Underline Science appeared first on The Scholarly Kitchen.
How to Evaluate a Modern Digital Preservation Platform
, updated:
Digital collections are growing faster than ever. Research data, institutional records, audiovisual collections, cultural heritage assets and born-digital archives continue to expand while expectations around accessibility, authenticity and long-term preservation become increasingly demanding. Yet many organizations still rely on storage systems or legacy tools that were never designed for the realities of modern digital preservation. […]
The post How to Evaluate a Modern Digital Preservation Platform appeared first on LIBNOVA.
How to Evaluate a Modern Digital Preservation Platform
Digital collections are growing faster than ever. Research data, institutional records, audiovisual collections, cultural heritage assets and born-digital archives continue to expand while expectations around accessibility, authenticity and long-term preservation become increasingly demanding. Yet many organizations still rely on storage systems or legacy tools that were never designed for the realities of modern digital preservation. […]
The post How to Evaluate a Modern Digital Preservation Platform appeared first on LIBNOVA.
Wellcome partners with IOI to map the data resources powering open research
, updated:
IOI's new initiative that maps the data resource ecosystem
The Hidden Political Costs of Vanishing Culture
, updated:
In a new article, “The Political Threats of Vanishing Culture and the Need to Protect Our Future Memory,” Michael Menna and Lila Bailey argue that the shift from buying physical […]
Guest Post — From Parasitism to Symbiosis: Escaping Peer-Pressure and For-Profit Publishers Through Diamond Open Access
, updated:
Two environmental researchers argue that open-access publishing has undergone major “environmental” shifts, triggering rapid and far-reaching evolutionary responses, not unlike natural ecocystems.
The post Guest Post — From Parasitism to Symbiosis: Escaping Peer-Pressure and For-Profit Publishers Through Diamond Open Access appeared first on The Scholarly Kitchen.
Google Summer of Code Contributors Improve Open Library’s Patron Experience
This year, as part of Google Summer of Code (GSoC), the Internet Archive is collaborating with two outstanding contributors to make it easier for patrons to find relevant books on Open Library. Tanishq Sangwan, a 19-year-old from Gurugram, India, and Chisom Nnamani of Lagos, Nigeria, are two of 1,141 software developers from around the world […]
Making research communication more equitable and effective: six levers to support preprint sharing [Originally published in the INASP blog in June/2026]
, updated:
Although most policymakers and research funders are committed to Open Access, many have not yet recognized the sharing of preprints as a key solution to the shortcomings of the current publishing system. INASP’s new policy paper outlines six measures to help policymakers and research funders support the sharing of preprints and drive change in the scientific publishing system. …Read More →
The post Making research communication more equitable and effective: six levers to support preprint sharing [Originally published in the INASP blog in June/2026] first appeared on SciELO in Perspective.
Building the State Case for ASAP Replication
, updated:
The City University of New York’s Accelerated Study in Associate Programs (ASAP) model offers one of the most rigorously tested initiatives available, proven to double graduation rates at CUNY and replication sites across the country. With support from ECMC Foundation, Ithaka S+R has worked with the CUNY ASAP replication team over the past year to build a suite of resources that help states and systems explore the benefits of CUNY ASAP by identifying the model’s potential to address the state’s specific needs and priorities.
The post Building the State Case for ASAP Replication appeared first on Ithaka S+R.
The Bookish Vacation That Reshaped Pop Culture
, updated:
This article first appeared in the July 2026 edition of our email newsletter.
The year: 1816. The night: dark and stormy. The players: Two illustrious poets, two wild young women with more raging em…
Who Validates the Validator?
, updated:
The federal government now allows agencies to destroy permanent records based on their own validation. The public record reveals what happened during the first year of that experiment.
Vanishing Culture Episode #3: Saving Queer Memory with Brooke Palmieri
, updated:
Queer history has often been overlooked, erased, or excluded from traditional archives. In the third episode of our special six-part series on Vanishing Culture, host Vida Vojić speaks with writer, […]
Google Summer of Code Contributors Improve Open Library’s Patron Experience
, updated:
This year, as part of Google Summer of Code (GSoC), the Internet Archive is collaborating with two outstanding contributors to make it easier for patrons to find relevant books on […]
Slow Food, Slow Publishing: The Beauty of Not Being First
, updated:
Robert Harington reflects on our addiction to speed and advocates for slow scholarly publishing and the inherent beauty of not always being first.
The post Slow Food, Slow Publishing: The Beauty of Not Being First appeared first on The Scholarly Kitchen.
Announcing the commonmeta schema 1.0 release candidate
, updated:
Commonmeta is a set of libraries to convert scholarly metadata into different formats via an intermediary format defined by JSON Schema. The schema is now available as a v1.0 version release candidate, with v1.0 planned to be released in September.
The feature image of this post is from
Strategies for Improving Outcomes for Part-Time Learners
, updated:
Our new report, Part Time, Full Potential: Strategies for Improving Outcomes for Part-time Learners, supported by Arnold Ventures, examines who part-time learners are, the barriers they face, and where targeted research and reform could have the greatest impact on improving their outcomes.
The post Strategies for Improving Outcomes for Part-Time Learners appeared first on Ithaka S+R.
Saving Tangible Media for Tomorrow: A Reflection from Natalie Nemes
, updated:
2026 Junior Fellow Natalie Nemes describes her work preserving tangible media items for future use and access and shares the history of the Library of Congress’s Tangible Media Project. Click through for more!
Rogue Scholar supports Crossref schema 5.5
, updated:
Yesterday the Rogue Scholar science blog archive started using Crossref schema 5.5 that was released last Friday.
The most relevant change in the new schema for Rogue Scholar is the introduction of a dedicated content type blog post (as type posted_content, subtype blog). This makes it easier to
Open Science 2.0: Building Understanding in an AI-Mediated World
, updated:
Open Science 2.0 must focus not only on access, but also on trust, interpretation, learning, and effective communication. The challenge facing the scholarly publishing ecosystem is ensuring that what is open is also trustworthy, understandable, and genuinely useful.
The post Open Science 2.0: Building Understanding in an AI-Mediated World appeared first on The Scholarly Kitchen.
The Last Appraisal
, updated:
Who decides whether a permanent record's original survives digitization?
ARL Daily Intelligence (July 13–16)
, updated:
Last Updated on July 18, 2026, 6:50 am ET The ARL Daily Intelligence is the trusted source of news and analysis for library leaders and advocates. Released Monday through Thursday, the ARL Daily...
The post ARL Daily Intelligence (July 13–16) appeared first on Association of Research Libraries.
Access to the Law Inside
, updated:
Our new report turns the spotlight on law librarians librarians and the work they do for patrons who are incarcerated. Drawing on a national survey of law libraries and in-depth interviews with librarians across the country, we document the current landscape of services for incarcerated patrons, the barriers librarians face, and the creative strategies they have developed to expand access to legal information despite limited resources and significant institutional constraints.
The post Access to the Law Inside appeared first on Ithaka S+R.
Guest Post — Research Needs a Shared Standard for AI Disclosure
, updated:
Today's guest post presents outcomes of the WCRI's (World Conferences on Research Integrity) Focus Track to address this gap in clarity and standardization of AI disclosure.
The post Guest Post — Research Needs a Shared Standard for AI Disclosure appeared first on The Scholarly Kitchen.
siegfried 1.11.5 released
Version 1.11.5 of siegfried is now available. Get it here.
CHANGELOG v1.11.5 (2026-07-11)
- update go version to 1.25.0
- update PRONOM to v124
- bug with mimeinfo signature generation. Reported by Hugh Williams
- wasm_exec.js updated. Reported by Trevor Munoz
Report: “Indiana Librarians to Get Mental Health Training”
, updated:
From the Indiana Capital Chronicle: Hoosiers suffering mental health crises are visiting public libraries for help — transforming the role of librarians who act simultaneously as researchers, archivists and quasi-social workers. Mental Health America of Indiana is stepping in to train librarians in how to respond to these crises and direct patrons to reliable information on […]
The post Report: “Indiana Librarians to Get Mental Health Training” appeared first on Library Journal infoDOCKET.
The OMB Guidance Revision Threatens All Research
, updated:
The OMB proposed revision is about all research — and humanities research is just as vulnerable as STEM.
The post The OMB Guidance Revision Threatens All Research appeared first on The Scholarly Kitchen.
When Search Becomes Inquiry
, updated:
What the Palme investigation archive reveals about the future of archival access
Guest Post — Why Research Libraries Oppose the OMB Revisions to the Uniform Guidance
, updated:
Today's post explains how the Association of Research Libraries (ARL) is responding to the proposed rule changes for US federal grants.
The post Guest Post — Why Research Libraries Oppose the OMB Revisions to the Uniform Guidance appeared first on The Scholarly Kitchen.
Schema 5.5 now available: adding CRediT, new record types for blogs and posters, and more
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Crossref Schema 5.5 includes several improvements across different content types, but its most significant enhancement is the expanded support for contributor roles through the introduction of multiple roles per contributor, option to specify the corresponding author, and compatibility with the CRediT (Contributor Roles Taxonomy): a community-owned taxonomy of 14 contributor roles, which has been adopted and made available in multiple languages.
These enhancements allow members to describe research contributions in much greater detail, creating richer metadata that better reflects how research is actually produced, and supporting greater accountability and more comprehensive research assessment.
If your workflow already distinguishes between different kinds of contributions, Schema 5.5 gives you a way to record that detail more accurately using the CRediT taxonomy values. CRediT can be adopted gradually, where it fits your editorial or production workflow.
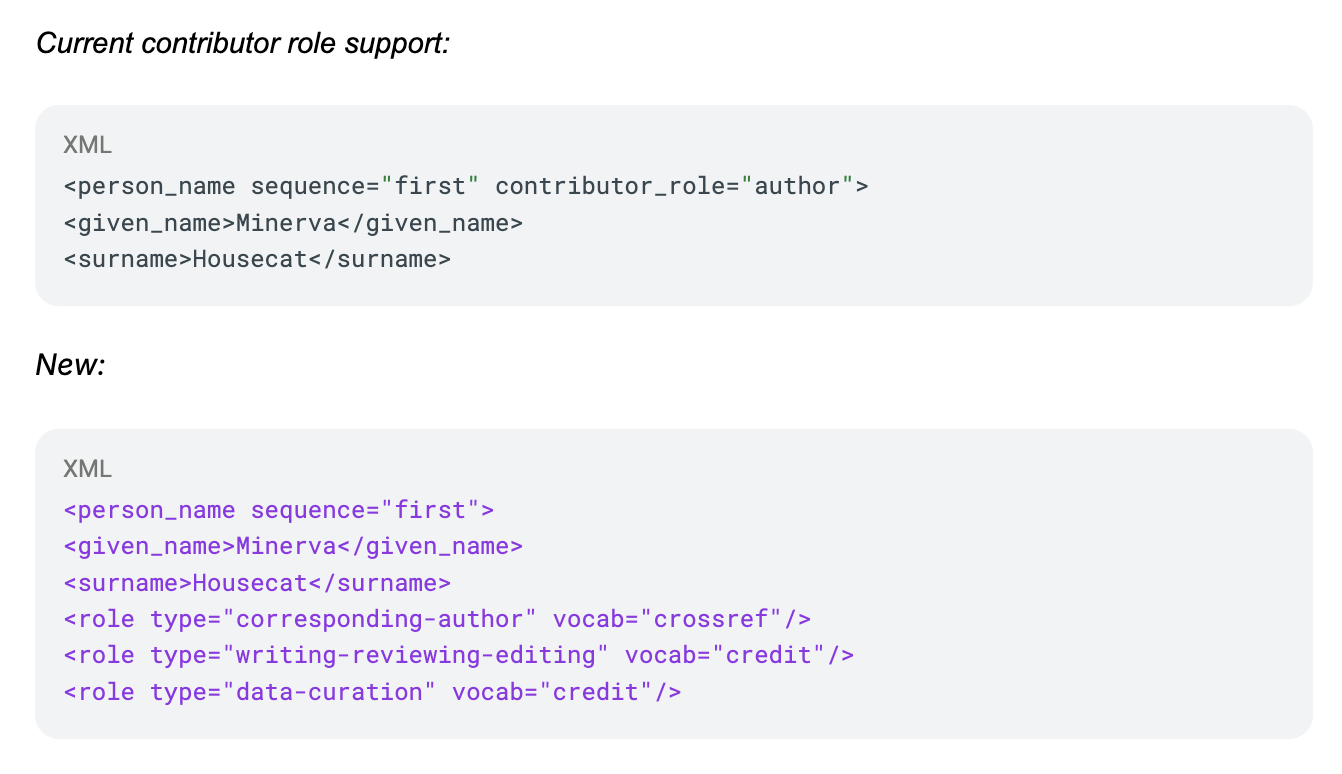
Figure 1: Until now, contributors could be assigned a single contributor role using Crossref’s existing contributor role vocabulary. In Schema 5.5, members can indicate that the same contributor was responsible for different roles, such as corresponding author; writing: reviewing and editing; and data curation.
Existing deposits remain fully supported, and members can continue using the current contributor role attribute while planning implementation of the new repeatable role type element. For our members, who have been using CRediT in their workflows already, as ever – we encourage updating your metadata when practicable.
Why this update is kind of a big deal
This update gives more accurate credit to all of the people behind research outputs. Crossref vocabulary includes roles that aren’t recognised in CRediT, and vice versa. Capturing richer contributor metadata recognises contributions that may not be visible in a single author line and improves transparency around how research is produced, thereby enabling downstream systems to interpret that information more reliably. The update also offers better interoperability with CRediT, which is well recognised across the scholarly ecosystem.

Figure 2: Schema 5.5 is an expansion of Crossref contributor metadata. Members can describe contributors using Crossref’s existing contributor role vocabulary, as well as the internationally recognised CRediT taxonomy.
In turn, this strengthens metadata reuse across repositories, discovery services, funders, institutions and other infrastructure providers; and supports evaluation, reporting and discovery workflows. Better contributor metadata strengthens the connections that make up the Research Nexus.
What else is included in Schema 5.5?
Beyond the expanded contributor support, Schema 5.5 includes several additional enhancements across the metadata schema.
1. Updates to report series metadata
Support has been added for metadata elements that were previously missing from report series records, including Crossmark, funding, and licence information.
2. Posted content improvements: now including blogs and posters
Posted content includes preprints, eprints, and other types of content that have been posted to a stewarded host platform. We’re all about persistence, so it’s vital that everything registered with us be maintained. Note that accepted manuscripts are not considered posted content. Schema 5.5 refreshes posted content sub-types by introducing blog and poster.
At the same time, we are “retiring” working paper, dissertation, and report from posted-content sub-types. Over time, these have been developed into separate record types that benefit from richer, dedicated schemas.
Finally, archive locations can now also be included for posted content records.
3. Expanded archive support
A new archive location, CINES, has been added to the list of supported archive providers.
4. Clinical trial metadata across more record types
Clinical trial information is no longer limited to journal articles and conference papers. Schema 5.5 extends support across additional content types, including books, datasets, dissertations, reports, posted content, standards, and pending publications.
Schema adoption
Taken together, the updates in our latest schema support more holistic recognition of contributions to the research and its communication, as well as greater accountability and integrity in related processes.
To support gradual adoption, Schema 5.5 maintains backwards compatibility with existing deposits. Members can continue using the current contributor_role attribute while preparing to implement the new repeatable role element. We have prepared a migration guide to help members transition to Schema 5.5.
As you prepare to adopt Schema 5.5, we encourage members to include contributor roles whenever they are available from editorial workflows and to use recognised vocabularies consistently, including CRediT roles where appropriate.
Reflections on the LIBER Annual Conference 2026
, updated:
Last week, we attended the LIBER annual conference in Trondheim, Norway. Our reasons for attending were twofold: (1) to present results from Ithaka S+R’s recent 2025 US Library Survey as part of the parallel session titled, “Research Libraries in Challenging Landscapes,” and (2) to learn from European colleagues about areas of convergence or difference between the activities and areas of focus of research libraries within the US and Europe.
The post Reflections on the LIBER Annual Conference 2026 appeared first on Ithaka S+R.
Vanishing Culture Episode #2: The Stories Hidden in Cookbooks with Katie Livingston
, updated:
Food is having a cultural moment. As America marks its 250th anniversary, new cookbooks celebrate endangered culinary traditions, UNESCO calls recipes “living heritage,” and chefs are rediscovering centuries-old techniques. But […]
Guest Post — Where Do We Go From Here? How Scientific Societies are Thinking about the Proposed OMB Funding Rule
, updated:
Today's post features conversations with society publishing leaders resisting the proposed OMB rule change for federal research funding.
The post Guest Post — Where Do We Go From Here? How Scientific Societies are Thinking about the Proposed OMB Funding Rule appeared first on The Scholarly Kitchen.
The Data Resilience Funding Landscape: A Preliminary Analysis
, updated:
Mapping where the money is (and isn't) going in the data rescue movement.
ALA’s Intellectual Freedom Committee Releases “New Guidelines to Support Library Staff in Evaluating Digital Content Vendors”
, updated:
Here’s the Full Text of Today’s Publication Announcement: The Intellectual Freedom Committee today announced the release of “Content Controls and Access Guidelines for Vendors,” a new guiding document designed to help library staff make informed, principled decisions when selecting third‑party digital content providers. Adopted on May 5, 2026, the guidelines equip library workers with essential tools to safeguard […]
The post ALA’s Intellectual Freedom Committee Releases “New Guidelines to Support Library Staff in Evaluating Digital Content Vendors” appeared first on Library Journal infoDOCKET.
Ask the Chefs: How Are You Responding to the OMB Proposed Rule Changes for US Research Funding?
, updated:
Today, we ask the Chefs how they (or their organizations) are responding to the proposed changes to how US federal research grant funds can be used.
The post Ask the Chefs: How Are You Responding to the OMB Proposed Rule Changes for US Research Funding? appeared first on The Scholarly Kitchen.
ARL Daily Intelligence (July 6–9)
, updated:
Last Updated on July 9, 2026, 4:16 pm ET The ARL Daily Intelligence is the trusted source of news and analysis for library leaders and advocates. Released Monday through Thursday, the ARL Daily...
The post ARL Daily Intelligence (July 6–9) appeared first on Association of Research Libraries.
ARL Libraries Celebrate America’s 250th Birthday
, updated:
Last Updated on July 15, 2026, 2:07 pm ET July 4, 2026, is the 250th anniversary of the signing of the Declaration of Independence, establishing the United States of America....
The post ARL Libraries Celebrate America’s 250th Birthday appeared first on Association of Research Libraries.
The Emotional Rollercoaster of Scholarly Publishing
, updated:
Today, we take an emotional journey through scholarly publishing and aim to understand how emotions impact authors', reviewers', and editors' experiences in the scholarly communications lifecycle.
The post The Emotional Rollercoaster of Scholarly Publishing appeared first on The Scholarly Kitchen.